By Evan Sangaline | September 19, 2017
One Million robots.txt Files
The idea for this article actually started as a joke.
We do a lot of web scraping here at Intoli and we deal with robots.txt files, overzealous ip bans, and all that jazz on a daily basis.
A while back, I was running into some issues with a site that had a robots.txt file which was completely inconsistent with their banning policies, and I suggested that we should do an article on analyzing robots.txt files because that’s pretty much the one file that we can be absolutely certain that we’re allowed to scrape from any domain.
And by “suggested,” I mean that I posted this on Slack.

We discussed it a bit and thought that it would be somewhat interesting to go through a large number of robots.txt files to pull out some of the most common patterns in terms of user agents, crawl delays, paths, etc.
So we set up a simple web scraper to download the robots.txt files from the Alexa Top One Million Websites and let it do its thing.
What we ended up finding when we ran over the data was that the things we thought would be interesting actually weren’t all that interesting!
It’s really hard to look at “the most common” anything in the data and see anything but consequences of the fact that many of the robots.txt files out there share common origins.
For example, countless sites out there use something pretty close to the default file that comes with WordPress and pretty much anything in there is going to be on the “most common” lists.
Instead of deciding that the article wasn’t worth pursuing, we were instead inspired to dig much deeper into the data to understand some of the more subtle structure of the dataset.
Overall, the analysis ended up being much more interesting than we were initially expecting.
You may have seen articles with similar premises before, but I can say with some confidence that we take the analysis to another level.
We’ll explore the history and development of robots exclusion policies as well as some of the more subtle components of structure within the dataset.
Read on and you’ll soon know more about robots.txt files than you ever realized there was to know.
Robots.what files?
If you’re reading this article then, chances are, you’re familiar with robot exclusion policies.
The basic gist of them is that webmasters, or whatever way less cool term you want to use for them, serve up a file called robots.txt from the root of their server that defines some guidelines for how robots should behave.
For example, the Intoli robots.txt file includes this text.
# "We hold these truths to be self-evident,
# that all bots are created equal."
# ~ Thomas Jeffersonbot
User-agent: *
Allow: *
Crawl-delay: 5
Sitemap: https://intoli.com/sitemap.xml
The User-agent: * directive is used to indicate that the following directives apply to all bots.
Allow: * then means that the bots are free to visit whichever URLs they would like and the Crawl-delay: 5 limits the request rate to at most one every five seconds.
The Sitemap: https://intoli.com/sitemap.xml points to a sitemap which helps bots find all of the content on the website without needing to crawl through links.
Any lines starting with # are comments and these are traditionally used for vague attempts at humor which signal to twenty-something white males that this is a “cool” place to work.
So that’s the stuff that you probably already know, but there is some history to them which is also sort of neat. For example, the story of science fiction writer Charles Stross instigating their creation when he unintentionally DOSed Nexor while trying to learn Perl back in 1993 or 1994. The thing that I love about that story is the informality of the circumstances. Martijn Koster calling up the person who was scraping him on the phone and then suggesting a bot etiquette practice on a www-talk mailing list for discussing “all things world wide web” really harks back to another time.
You might expect that the next step of the story involves some sort of standardization, but that actually never quite happened.
Despite being commonly called the “Robots Exclusion Standard,” robots.txt files are only a de facto standard at best and, even then, not all that standard.
The original, and relatively informal, proposal from 1994 only covers the most basic components of User-agent, Allow, and Disallow directives.
Martijn followed up with a more formal Internet Draft (ID) in 1996 which added more explicit guidelines for end-of-line indicators, octet encoding, cache expiration, and other details.
That ID never became even an RCF, let alone an Internet Standard, and adherence to the draft spec was spotty at best for many years.
It even says in that document that “it is inappropriate to use Internet-Drafts as reference material or to cite them other than as work in progress.”
The history gets a bit murky for about a decade after 1996.
Many news articles and blog posts from that period are simply no longer available and, for the life of me, I can’t find anything about when or how the Crawl-delay directive came into common usage.
The next steps towards standardization began when Google, Yahoo, and Microsoft came together to define and support the sitemap protocol in 2006.
Then in 2007, they announced that all three of them would support the Sitemap directive in robots.txt files.
And yes, that important piece of internet history from the blog of a formerly 125 Billion dollar company now only exists because it was archived by Archive.org.
This loose coalition of search engines then came together again in 2008 to announce that a set of common robots.txt directives that they would all support.
To this day, that blog post is probably the closest to standardization that robots exclusion policies have ever gotten.
It pledged unanimous support for the User-agent, Allow, Disallow, and Sitemap directives with both $ and * wildcard support.
This announcement is interesting, in part, because it gives some insight into the differences between how the search giants handled the directives prior to the announcement in addition to after.
Notably, Microsoft had previously not been supporting the Allow directive or the use of * wildcards.
Both Yahoo and Microsoft had been supporting the Crawl-delay directive, but Google had not and, in fact, refused to agree to it moving forward.
To this day, Google still does not support the Crawl-delay directive!
So even among the search giants there has never really been any complete agreement on what should or shouldn’t be respected in a robots.txt file.
There’s even less consensus when you consider the broader range of bots which can range from massive internet-wide web crawlers down to browser extensions which slightly augment and extend a human’s interaction with a website.
Any webmaster worth their salt could tell you that robots.txt files are seldom respected by smaller web scrapers, but this is becoming increasingly common for larger projects as well.
In January 2017, Apple stated that it’s Applebot scraper will scrape anything that is allowed for Googlebot if it isn’t explicitly forbidden by name (in other words, it basically won’t respect Disallow directives for User-agent: *).
Similarly, the director of The Wayback Machine, Mark Graham, announced that Archive.org will no longer respect robots.txt files.
And should they?
Would it really make sense for Yahoo’s announcement of the Sitemap directive in robots.txt files to be lost to the sands of time, just because Verizon decides they no longer want the historical Yahoo blog archives to be indexed?

Somewhat surprisingly, it’s even fairly well-established that there’s no legal obligation in the United States to follow a robots exclusion policy.
Maybe that shouldn’t be that surprising given their history and lack of real standardization, but this is, after all, the land of “you’re violating copyright law every time you visit a website because you’re making an unauthorized copy in your computer’s RAM” (and the home of the brave).
Despite that, it’s quite clear that robots.txt files simply lay out proper etiquette and nothing beyond that.
One thing that we’ve been increasingly noticing here at Intoli is a trend towards webmasters putting arcane rules in place to initiate IP bans, or to whitelist certain bots, while not even bothering to put any restrictions in a robots.txt file.
Putting these sort of automated restrictions in place is certainly a reasonable thing for them to do, and perhaps even a necessity given how common misbehaved bots are, but the complete lack of communication regarding what sort of access is acceptable only serves to further degrade what little sanctity remains in the concept of robots exclusion policies.
It sadly seems that peoples’ faith in robots.txt has been gradually eroding across the board; both on the parts of bot and site operators.
Getting the data
The first thing that we need is a large collection of websites. There are a few big lists floating around, the most well-known of which is probably Alexa’s Top One Million Websites. As of April 29th, 2016, Alexa’s website stated that this list was freely available via s3.
You can get also get the global Top 1,000,000 Sites list for free directly from Alexa at http://s3.amazonaws.com/alexa-static/top-1m.csv.zip. The free Top 1,000,000 Sites list is based on the global 1 month average Traffic Rank.
This message has since been removed, but the data is still available in the alexa-static s3 directory (though it may not have been updated over the last year).
The data can be downloaded and extracted from s3 by running
# download and extract the Alexa top one million sites
wget http://s3.amazonaws.com/alexa-static/top-1m.csv.zip
unzip top-1m.csv.zip
# preview the top ten websites on the list
head top-1m.csv.zip
which will reveal a peak into the contents of the file.
1,google.com
2,youtube.com
3,facebook.com
4,baidu.com
5,wikipedia.org
6,yahoo.com
7,google.co.in
8,qq.com
9,reddit.com
10,taobao.com
You can see that it’s a simple CSV where the first column is the website rank and the second is the bare domain.
To collect the robots.txt files for all of these domain, we simply have to make HTTP requests to http://{domain}/robots.txt for each of them.
My first thought was that it should be possible to parallelize these requests because we only need to hit each server once and blocking therefore shouldn’t be an issue.
I was all ready to show off python’s shiny new asyncio features, and I put together a script that heavily parallelized the requests, but then quickly discovered that things weren’t so simple.
The web servers might not have cared about the traffic, but it turns out that you can only look up domains so quickly before a DNS server starts to question your intentions!
After realizing my mistake, I opted for simplicity and just made the requests sequentially using the following script.
import json
import sys
from urllib import request
from tqdm import tqdm
output_filename = 'robots-txt.jl' if len(sys.argv) != 2 else sys.argv[1]
with open('top-1m.csv', 'r') as f_in:
with open(output_filename, 'a') as f_out:
for line in tqdm(f_in, total=10**6):
rank, domain = line.strip().split(',')
url = f'http://{domain}/robots.txt'
try:
with request.urlopen(url, timeout=10) as r:
data = r.read()
text = data.decode()
url = r.geturl()
except:
text = None
f_out.write(json.dumps({
'rank': int(rank),
'domain': domain,
'url': url,
'robots_txt': text,
}) + '\n')
It’s slow as can be, but it completely avoids the issue of DNS lookups failing due to high volume.
Parsing the robots.txt files
Python–being batteries included and all–actually comes with a builtin robots.txt parser in urllib.robotparser.
RobotFileParser is great for fetching robots.txt files and then determining whether or not your bot is prohibited from accessing certain paths, but it’s functionality is relatively limited beyond that.
It got a lot better after they finally added support for Crawl-delay in python 3.6, but it still notably doesn’t support sitemaps.
There are two main alternatives to urlib.robotparser: reppy and robotexclusionruleparser.
Reppy seems like a great project for practical purposes, but it’s less hackable because it’s written in c++.
I decided to go with robotexclusionruleparser instead so that I could add functionality more easily.
Subclassing RobotExclusionRulesParser and adding some additional features only took a few dozen lines of code.
The main thing that I wanted to add was comment parsing, but, I made a few other changes while I was in there.
Namely, I modified the constructor to more closely match the format of the JSON Lines data file, added missing and html fields which indicate that robots.txt file either wasn’t present or contained HTML, and added line_count attribute to indicate the size of the file.
from robotexclusionrulesparser import RobotExclusionRulesParser, _end_of_line_regex
class RulesParser(RobotExclusionRulesParser):
def __init__(self, domain, rank, url, robots_txt):
super().__init__()
self.domain = domain
self.rank = rank
self.url = url
self.lines = []
self.comments = []
self.line_count = 0
self.missing = False
self.html = False
self.parse(robots_txt)
def parse(self, text):
if not text:
self.missing = True
return
elif '<html' in text or '<body' in text:
self.html = True
return
super().parse(text)
self.lines = _end_of_line_regex.sub('\n', text).split('\n')
for line in self.lines:
line = line.strip()
self.line_count += 1
if line.startswith('#'):
self.comments.append(line[1:].strip())
Then it was just a matter of looping through the already scraped robots.txt files and passing them into the parser constructor.
import json
from tqdm import tqdm
def load_robots_txt(filename='data.jsonl'):
with open(filename, 'r') as f:
for line in tqdm(f, total=10**6):
yield RulesParser(**json.loads(line))
General Overview
A natural starting point for looking at the data is to compute some summary statistics.
Looping through the data is easy using the load_robots_txt() generator that we defined earlier.
from collections import defaultdict
totals = defaultdict(int)
for robots_txt in load_robots_txt():
if robots_txt.missing:
totals['missing'] += 1
if robots_txt.html:
totals['html'] += 1
if len(robots_txt.sitemaps) > 0:
totals['sitemaps'] += 1
totals['all'] += 1
print(totals)
The above code will pull out some key numbers.
{
"all": 1000000,
"html": 41186,
"missing": 386536,
"sitemaps": 231658
}
Of the one million robots.txt files that were requested, 38.65% of them returned 404 or had some other error occur.
I thought about renaming the article to “Analyzing 613,464 Robots.txt Files” because of this, but it just didn’t have the same ring to it.
It’s reasonable to expect that some fraction of those missing robots.txt files were caused by transient errors and so I took a random sampling of those domains and rerequested their files.
Roughly 2.9% of the sites returned something valid on the second request, so running over all of them would be expected to turn up about 11k additional files.
This would only extend the dataset of valid files by 1.8% or so, and I decided it wasn’t worth the relatively large time investment for such a marginal increase in available data.
Of the valid responses that were received, 41,186 of them returned what appeared to be HTML content.
These generally correspond to servers that forward any unmatched URLs to their main page instead of returning 404 errors.
Subtracting these off, we are left with 572,278 responses that appeared to be legitimate robots.txt files.
For all of the analysis that follows, we’ll only be considering only these domains for which there were valid responses containing no HTML.
The last general statistic that I tallied was the number of sites that listed sitemaps in their robots.txt files.
That total was 231,658, or about 37.8% of the sites with valid robots.txt files.
Let’s dig a little deeper by removing the domain and looking at the most common locations for sitemap files.
from collections import Counter
from urllib.parse import urlparse
sitemap_counter = Counter()
for robots_txt in load_robots_txt():
sitemap_paths = map(lambda url: urlparse(url).path, robots_txt.sitemaps)
sitemap_counter.update(sitemap_paths)
print(sitemap_counter.most_common(10))
| Sitemap Path | Occurrences |
|---|---|
| /sitemap.xml | 177964 |
| /news-sitemap.xml | 11147 |
| /sitemap_index.xml | 11045 |
| /SiteMap.aspx | 10118 |
| /sitemap.xml.gz | 9690 |
| /sitemap | 6954 |
| /index.php | 4187 |
| /dynamic-sitemaps.xml | 3533 |
| /robots.txt | 3510 |
| /sitemapindex.xml | 3062 |
We can see that, perhaps unsurprisingly, sitemap.xml is used in the vast majority of cases that a sitemap is present.
Most of the others are variations on that theme and several, such as SiteMap.aspx imply dynamically generated content.
It’s interesting that index.php and robots.txt are so high up the list though, as both of these appear to miss the point of including the Sitemap directive.
Robots.txt Comments
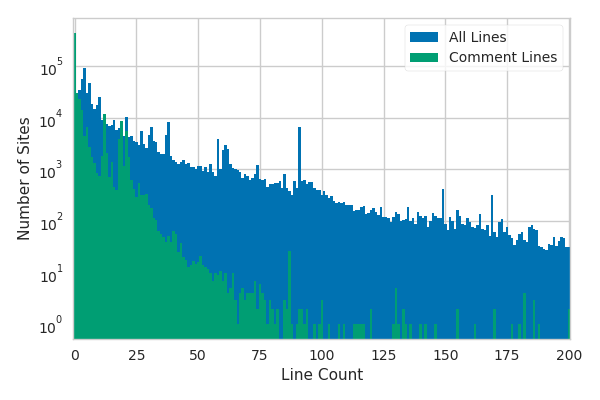
Comments are fairly commonplace in robots.txt files and I was curious to see if any interesting commonalities would spring up in them.
Unfortunately, the most common comments were, for the most part, fairly boring.
The majority of the comments are basically boilerplate that gets passed around when people copy the contents of robots.txt from other sites or look up templates.
Certain software, such as MediaWiki, comes with default robots.txt files that are then widely used.
I’ll get into this in more detail later and the figure above will actually come back to play a key role there.
I could only really find anything worth mentioning in the comments when I specifically looked for it.
For example, filtering on “a robot may not injure a human being” revealed this in Yelp’s robots.txt:
# As always, Asimov's Three Laws are in effect:
# 1. A robot may not injure a human being or, through inaction, allow a human
# being to come to harm.
# 2. A robot must obey orders given it by human beings except where such
# orders would conflict with the First Law.
# 3. A robot must protect its own existence as long as such protection does
# not conflict with the First or Second Law.
The same joke turned up on 58 of the one million sites (though to be fair, just over half of those are Yelp with different country TLDs).
I found it somewhat amusing that muenchnersingles.de, stuttgartersingles.de, and wienersingles.at were all among those 58.
It’s probably no secret that they’re run by the same people, but what better way to learn that they are than searching for Asimov’s Three Laws in robots.txt files?
The most shocking thing that I discovered about robots.txt comments was that profanity is extremely rare.
I thought that it would be a good way to find people frustrated with specific bots, but only nine of the files contained the word “fuck” in the comments.
I literally went through my code to make sure that there wasn’t a bug when I saw a number that small.
I’m glad that I searched for profanity though, because I found one robots.txt that I particularly liked.
It’s from the guys who make VLC over at videolan.org and the contents are as follows.
# "This robot collects content from the Internet for the sole purpose of
# helping educational institutions prevent plagiarism. [...] we compare
# student papers against the content we find on the Internet to see if we
# can find similarities." (http://www.turnitin.com/robot/crawlerinfo.html)
# --> fuck off.
User-Agent: TurnitinBot
Disallow: /
# "NameProtect engages in crawling activity in search of a wide range of
# brand and other intellectual property violations that may be of interest
# to our clients." (http://www.nameprotect.com/botinfo.html)
# --> fuck off.
User-Agent: NPBot
Disallow: /
# "iThenticate® is a new service we have developed to combat the piracy
# of intellectual property and ensure the originality of written work for#
# publishers, non-profit agencies, corporations, and newspapers."
# (http://www.slysearch.com/)
# --> fuck off.
User-Agent: SlySearch
Disallow: /
The reason that I liked this one so much is that it seems to be borne out of principled opposition to the bots rather than mere frustration. That’s something that I can respect.
User Agent Specific Rules
Now, let’s take a look at some of the actual rules and directives inside of the robots.txt files.
We’ll start by looking at the twenty most commonly referenced user agents and how many corresponding Allow and Disallow rules they each have
| User Agent | Total | Allow Counts | Disallow Counts | Allow/Disallow |
|---|---|---|---|---|
| Mediapartners-Google* | 18920 | 4152 | 14768 | 0.28 |
| Googlebot-Mobile | 26625 | 4751 | 21874 | 0.22 |
| Googlebot | 340185 | 38740 | 301445 | 0.13 |
| Mediapartners-Google | 73376 | 7879 | 65497 | 0.12 |
| * | 6669397 | 702888 | 5966509 | 0.12 |
| Googlebot-Image | 99444 | 9625 | 89819 | 0.11 |
| Mail.Ru | 23161 | 2203 | 20958 | 0.11 |
| AdsBot-Google | 19163 | 1278 | 17885 | 0.07 |
| Yandex | 380945 | 22728 | 358217 | 0.06 |
| bingbot | 67560 | 3026 | 64534 | 0.05 |
| ia_archiver | 25585 | 1093 | 24492 | 0.04 |
| Yahoo! Slurp | 18180 | 716 | 17464 | 0.04 |
| Baiduspider | 29339 | 968 | 28371 | 0.03 |
| msnbot | 64826 | 2005 | 62821 | 0.03 |
| Slurp | 77745 | 2258 | 75487 | 0.03 |
| MSNBot | 18674 | 390 | 18284 | 0.02 |
| MJ12bot | 22678 | 121 | 22557 | 0.01 |
| AhrefsBot | 24014 | 36 | 23978 | 0.00 |
| Exabot | 18194 | 24 | 18170 | 0.00 |
| adsbot-google | 47388 | 28 | 47360 | 0.00 |
You can see that I’ve sorted these by their ratio of Allow rules over Disallow rules to give some approximation of how favorably site operators view the different bots.
Things are a bit more complicated in reality because of the use of wildcards, but it does certainly seem that Google bots tend to be preferentially whitelisted over those of other search engines.
Perhaps Google privilege has its limits though, as apparently MSNBot is generally allowed a smaller crawl delay.
| User Agent | Median Crawl Delay | Mean Crawl Delay |
|---|---|---|
| MSNBot | 3.0 | 133.25 |
| adsbot-google | 4.0 | 4.00 |
| Mail.Ru | 5.0 | 46.36 |
| Mediapartners-Google | 5.0 | 76.83 |
| Googlebot | 5.0 | 382.82 |
| Mediapartners-Google* | 10.0 | 29.73 |
| AdsBot-Google | 10.0 | 15.97 |
| ia_archiver | 10.0 | 1011.69 |
| Googlebot-Mobile | 10.0 | 72.51 |
| bingbot | 10.0 | 96.76 |
| Slurp | 10.0 | 268.15 |
| Yandex | 10.0 | 32.28 |
| * | 10.0 | 126.66 |
| Googlebot-Image | 14.0 | 173.47 |
| MJ12bot | 20.0 | 1230.61 |
| Yahoo! Slurp | 30.0 | 67.27 |
| Exabot | 30.0 | 31.47 |
| AhrefsBot | 30.0 | 141.13 |
| Baiduspider | 30.0 | 167.92 |
| msnbot | 30.0 | 341.67 |
Except that if you capitalize it as msnbot then it has a significantly longer crawl delay.
Oh, and it’s been retired since 2010.
One of the most concrete inferences that you can draw from this data is actually that many of these files are woefully outdated.
There are enough outliers that the averages are basically meaningless, and there are again some subtle issues that arise with wildcards and missing crawl delays. It’s fun to look at the tables, but these really need to be taken with a grain of salt.
The Duplicate Content Issue
I’ve hinted at this a few times already, but it’s time to dive right into it.
There is a lot of duplicate robots.txt content out there and this makes it really difficult to look at aggregate statistics about directives without the results being heavily biased by this fact.
This applies to the tables we’ve looked at already and it would apply equally to really most of the things we might be interested in looking at.
Let’s look at a concrete example to make it more clear how this effect comes into play.
Say that we’re curious what the most commonly used lines in robots.txt are.
This can be computed easily enough.
from collections import Counter
line_counter = Counter()
for robots_txt in load_robots_txt():
line_counter.update(robots_txt.lines)
print(line_counter.most_common(10))
| Line | Occurrences |
|---|---|
| "" | 1915358 |
| "Disallow: /" | 693508 |
| "User-agent: *" | 503109 |
| "#" | 164082 |
| "Disallow: /wp-admin/" | 121177 |
| "Disallow:" | 111752 |
| "Allow: /wp-admin/admin-ajax.php" | 90985 |
| "Allow: /" | 89984 |
| "Disallow: /admin/" | 55936 |
| "Disallow: /includes/" | 51590 |
Most of these aren’t particularly surprising, but what about Allow: /wp-admin/admin-ajax.php?
Doesn’t that seem oddly specific to be more common than Disallow: /admin/?
The path itself is a bit of a give-away, but a quick search for the path turns up a WordPress ticket stating
As plugins are using admin-ajax.php on the frontend, we should add
Allow: /admin/admin-ajax.phpTo the default robots.txt to prevent Google from sending out million of emails, see this article: https://www.seroundtable.com/google-warning-googlebot-css-js-20665.html
As you might have guessed, that ticket has since been closed.
So is this really that big of a deal?
It depends how you look at it.
The tables aren’t wrong necessarily, they’re just heavily influenced by widely circulated robots.txt files in a fairly opaque way.
I would personally find it a lot more meaningful to look at results separately for files which were inherited as project defaults and ones which were written fresh.
At the very least, it’s an interesting challenge to try to disentangle these effects.
Let’s revisit that distribution of line counts that we looked at earlier.
I didn’t want to get into the subtleties of it yet at that point, but you might have noticed that there were some tiny peaks along the distribution that are much larger than what could be explained by statistical noise.
These peaks are caused by duplicate, or at the very least similar, robots.txt files from multiple sites.
Let’s take another look at the distribution of line counts, this time zoomed in further so we can see a few peaks more clearly.
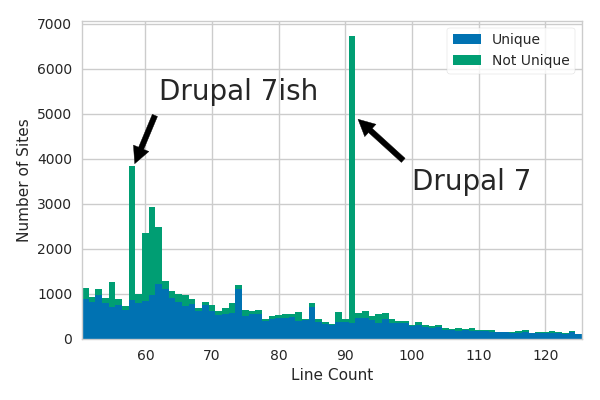
This time the histogram has also been split into two stacked components: robots.txt files that appear verbatim on multiple sites and ones that are unique across all sites.
You can see that the major peaks in this region of line counts seem to be almost entirely the result of the non-unique files.
I Googled excerpts from two of the peaks and traced them back to the default Drupal robots.txt files.
One is an exact match on Drupal 7.x while the one labeled “Drupal 7ish” appears to be a common variant of the same file with a chunk of Allow directives removed.
It would clearly be a major step in the right direction to simply deduplicate the contents of the robots.txt files, but there are some more subtle effects that this wouldn’t remove.
For one thing, there are a number of narrow peaks, such as the ones at line counts of 74 and 85, which are not attributable to exactly duplicate files.
These could be caused by templated robots.txt files that include custom sitemaps or comment headers for example.
There are also relatively broad excesses–like the one to the right of the main Drupal 7 peak with a line count of 92–which are probably caused by people adding a few custom lines to the default Drupal 7 file.
In order to identify and exclude these particular files, we would have to come up with some way to identify them as being based on the default Drupal 7 file.
One way to do this is to look for some unique text present in the default file in each robots.txt file and then consider anything that includes it to be based on the default.
A good candidate string for this approach is the introductory comment:
# This file is to prevent the crawling and indexing of certain parts
# of your site by web crawlers and spiders run by sites like Yahoo!
This seems unlikely to be reproduced verbatim by mere chance (unlike many crawl directives which tend to be more generic).
That might work for Drupal, but what about all of the other frameworks buried in there?
While Drupal is common enough to have very noticeable peaks, others might be too broad to discern or be hidden behind the statistical fluctuations.
We’ll need a more general approach if we want to identify some of the less obvious robots.txt templates.
A natural next step beyond looking for files that share a common string is to simply look for files that are similar.
All of the files based on the Drupal default will likely share much of the same content.
We would also expect this to be true of any other collection of files sharing a common origin.
Identifying and removing any clusters of similar files should effectively leave us with the robots.txt files that were written mostly from scratch.
We just need to decide exactly how we want to define similar and cluster in order to actually do this.
A common metric used to measure string dissimilarity is the Levenshtein distance. The Levenshtein distance is defined as the minimum number of character insertions, deletions, or substitutions required to change one string into another. For example, “missallanious” requires three substitutions to become “miscellaneous”. The two strings are therefore separated by a Levenshtein distance of 3. As you might imagine, this sort of distance metric is commonly used in spelling correctors.
In theory, we could just directly compute the Levenshtein distance between each pair of robots.txt files, but this actually ends up being impractical due to the computational complexity.
For two strings $a$ and $b$, the Levenshtein distance between the first $i$ characters of $a$ and the first $j$ characters of $b$ can be defined recursively as
where $\delta_{a_i b_j}$ is the Kronecker delta defined as $1$ when $a_i = b_j$ and $0$ otherwise. A direct recursive implementation of this can be as slow as $O(3^{\max,{|a|,|b|}})$ because each evaluation requires three additional recursive function calls.
The complexity can be improved to $O(|a||b|)$ with a more efficient algorithm, but it’s still extremely slow when the strings are thousands of characters long. Like 8.29 years slow. That’s how long it would have taken to evaluate all of the distance pairs on my computer using an efficient c++ implementation of the $O(|a||b|)$ algorithm. And I thought I waited a long time for all of the files to download in the first place!
Luckily, character-level distances are probably overkill for what we’re trying to accomplish here.
Most of the modifications to default robots.txt files tend to take place on the level of lines, rather than of characters, because people typically add or remove entire directives.
Even aside from that, the number of lines that have changed are actually kind of more meaningful for our purposes than the number of characters.
For example, Allow: * and Allow: /users/ have a character-level distance of 7 while Allow: * and Allow: /longer/path/to/users/ have a character-level distance of 22.
The character-level distance will clearly have major contributions from path lengths while, intuitively, that information is fairly superfluous to whether two files share a common origin.
Now that we’ve absolutely established that line-level distances are the better approach–and that I’m definitely not just rationalizing things ex post facto–let’s look at how we can actually implement this. We don’t actually have to change the Levenshtein distance algorithm at all, we just have to consider the lines in each file to be the discrete units instead of characters. We could even just do this directly, the only minor issue is that the string comparisons to compute $\delta_{a_i b_j}$ will be extremely slow.
The distance calculation can be sped up significantly by tokenizing the lines first so that only integers need to be compared instead of strings.
This is fairly straightforward given the line_counter object that we populated earlier.
import editdistance
# build the token map
line_to_int = {}
for i, (line, count) in enumerate(line_counter.items()):
line_to_int[line] = i
# define tokenization functions
def tokenize_line(line):
return line_to_int[line]
def tokenize_robots_txt(robots_txt):
return list(map(tokenize_line, robots_txt.lines))
# compute the line-level Levenshtein distance between files
def robots_txt_distance(robots_txt_1, robots_txt_2):
return editdistance.eval(tokenize_file(robots_txt_1), tokenize_file(robots_txt_2))
That’s a good start, but if we want to compute all of the pairwise distance then it makes sense to tokenize all of the files first so that we don’t have to retokenize each one thousands of times.
import numpy as np
# restrict the files to the Drupal region of line counts
line_range = (51, 125)
# pre-tokenize all of the files
tokenized_files = []
for robots_txt in load_robots_txt():
if line_range[0] <= len(robots_txt.lines) <= line_range[1]:
tokenized_files.append(tokenize_robots_txt(robots_txt))
# compute the pair-wise distance matrix
distances = np.zeros([len(tokenized_files)]*2)
for i, tokenized_file_1 in enumerate(tokenized_files):
for j, tokenized_file_2 in enumerate(tokenized_files):
# the matrix is symmetric so only compute the upper diagonal
if j < i:
continue
distances[i,j] = editdistance.eval(tokenized_file_1, tokenized_file_2)
# copy over to the lower diagonal
distances[j,i] = distances[i,j]
You’ll notice that I restricted the files to ones with line lengths in the range of the plot where I pointed out the Drupal peaks. This reduces the number of files we’re considering to roughly 10% of the total which in turn reduces the memory usage of the distance matrix to 1% of what it would be without the restriction. Doing this allowed me to keep everything in RAM, but it’s also nice that it will let us investigate those same Drupal peaks more closely. Totally not rationalizing.
OK, so we’ve measured the similarity between all of these files… now what? This gigantic distance matrix encodes a lot of information, but there’s so much there that it’s not very helpful by itself. Let’s start with just trying to distill the information into something that we can visualize and understand more easily.
When we think of discrete items and the distances between them, we probably most commonly think of them existing in some N-dimensional space and the distance being a standard Euclidean distance.
We effectively embedded the robots.txt files in a 125-dimensional space when we did the tokenization, but the Euclidean distance in that space was meaningless because of how we encoded values along each dimension.
If we want to visualize the data in a more meaningful way then we’ll need to transform it to a space where the Euclidean distance between files correlates more closely to the Levenshtein distance (which we chose specifically because it accurately represents dissimilarity in an intuitive way).
In other words, we want files that share a lot of content to be close to each other and files that are really different to be far away from each other.
Oh, and it wouldn’t hurt if this new space had fewer than 125 dimensions either as far as visualization goes.
What I just described is essentially dimensional reduction, and there’s one dimensional reduction algorithm that applies really well for our specific use-case: t-distributed Stochastic Neighbor Embedding (t-SNE). It’s generally one of the more effective dimensional reduction algorithms, but it’s a particularly good choice in this case for two reasons:
- It doesn’t require the initial data to be embedded in an already meaningful space. Instead, it’s only concerned with the pairwise distances between points. Those are exactly what we computed using the Levenshtein distance.
- It heavily prioritizes preserving short-distance structure over long-distance structure.
We’re primarily interested in the clusters of
robots.txtfiles that are based on defaults, so we don’t really care about the long-distance structure much at all.
Finding a low-dimensional t-SNE for our distance matrix will therefore allow us to visualize the structure around clusters of similar robots.txt files.
The basic idea behind the algorithm is pretty simple: you essentially use a Gaussian kernel to translate the pairwise distance into conditional pairwise probabilities representing similarity and then try to minimize the Kullback-Leibler divergence between those probabilities and the pairwise probabilities of points embedded in a low-dimensional space using a Student-t distribution. The heavier tails of the Student-t distribution result in the divergence between the probability distributions being relatively insensitive to the long-distance structure. You could just as easily use Gaussians in each case and simply ignore distances beyond some threshold, the idea is just to heavily prioritize the near-distance structure. The one tricky part is choosing the width of the kernel because it needs to be adapted to the density of the data. This is typically done by solving for the width that results in a predefined perplexity for the conditional pairwise probabilities.
There are also some implementation details that are important if you’re concerned with memory and CPU usage.
I used the scikit-learn implementation which supports using the Barnes-Hut algorithm for approximating the optimization procedure.
This reduces the runtime from $O(N^2)$ to $O(N\log(N))$, where $N$ is approximately 100,000 in our case, and should reduce the memory usage from $O(N^2)$ to $O(n)$.
The Scikit implementation, up until very recently, actually used a dense matrix representation instead of a sparse one and this had been an open issue for quite a while.
I mention this because the Barnes-Hut memory usage was pushing my computer over the edge and I ended up having to compile Thomas Moreau’s partially completed optim_tsne branch to make things barely fit.
In just the last week or so, the optimization pull request was accepted and you can now take advantage of that sparse matrix goodness if you install the beta version of scikit using pip install scikit-learn==0.19b2.
So without further ado, we can simply run
from sklearn.manifold import TSNE
tsne = TSNE(n_components=2, perplexity=30, metric='precomputed',
method='barnes_hut', n_iter=10**5, verbose=2)
result = tsne.fit_transform(distances)
to find our two dimensional embedding of the robots.txt files (after many hours and 16650 iterations).
The result of this dimensional reduction will allow us to finally visualize the structure of the files!
When I showed this plot to George Smoot, he told me that he thought it looked like the face of God, but I don’t see the resemblance personally.
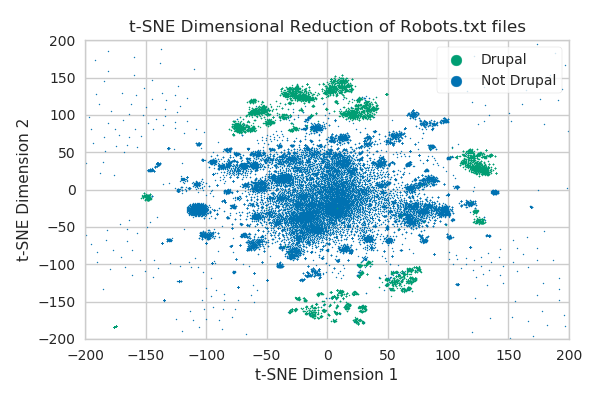
This is basically just a direct scatter plot of the result array with the scale zoomed in on the clustered structures.
The Drupal-based files have been separately identified based on the presence of that comment about “Yahoo!” that we saw earlier.
The fact that these all of the Drupal files fall into discernible clusters is a nice confirmation that these clusters are indeed meaningful.
Keep in mind that this is limited to the 51-125 line range, so it corresponds directly with the plot where we discussed the Drupal peaks. I can count maybe six or seven features in that distribution that I would consider to be unique peaks, but our t-SNE reveals that there are dozens of Drupal-based clusters alone. There are easily over a hundred clusters here overall and there’s no way that we would have been able to detect them in the same way that we initially detected Drupal.
Now that we’ve identified these clusters, what if we want to filter them out like we did earlier with duplicate files? This is primarily just a matter of coming up with a more rigorous definition for what it means to be part of a cluster and then limiting our analysis to the files which don’t satisfy that criteria. One relatively straightforward way that we can accomplish this is to estimate how densely populated the files are at different locations and only consider the files in sparser regions.
Let’s give this approach a shot using kernel density estimation with a Gaussian kernel. Loosely based on the size of the clusters in the t-SNE plot, I chose a standard deviation of 10 to use for the kernel. I then introduced a sparseness constraint where the local density around a file to be analyzed can’t exceed 110% of its own contribution to the density. This is a fairly stringent definition of sparseness, but it should ensure that we end up with files that really are quite unique.
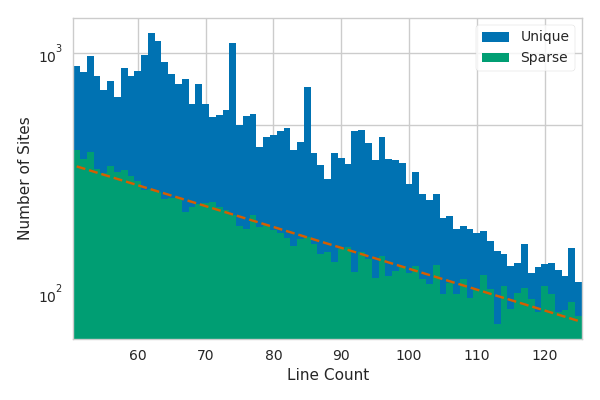
The distribution over line numbers for unique and sparse files shows us that virtually all of the local structure has been eliminated with the sparseness constraint. The sparse files appear to approximately follow an exponential distribution in this region as evidenced by the dashed line. I’m not sure that we should necessarily expect the distribution to be exponential, but the agreement with the fit does really emphasize the lack of local structure.
Another important thing to notice in this plot is that the sparseness constraint filters out a significantly larger fraction of files at lower line counts than at higher ones. The plot is logarithmic, so this is implied by the narrowing of the gap between the two distributions at large line counts. This effect is a consequence of the densities being naturally higher around shorter files. Consider the case of a file with a single line. Every single file with less than ten lines will fall within our kernel width and the local estimate of the density will be tremendous. We could reasonably expect that no files would pass the sparseness constraint with small line counts.
This isn’t just an artifact of the density estimation either; the densities themselves are genuinely higher for those shorter files. We could make both our kernel width and our maximum density adaptive, but there’s just fundamentally less information to go on for the shorter files. Those sort of improvements would simply give our filter less false negatives in exchange for more false positives without addressing the underlying issue that the shorter files are inherently more difficult to differentiate.
I’m tempted to include some of the updated tables with a sparseness constraint… but I won’t.
The vast majority of robots.txt files are relatively short and I’m not convinced that there’s a meaningful way to extend the methodology that we’ve explored here to include these.
I hope that you still found our exploration of structure and clustering in the dataset interesting, even if it didn’t result in a silver bullet approach for filtering out all files based on templates!
Wrap Up
Congratulations, you’ve reached the end of Part 1 in our 8 part series on robots.txt files!
Just kidding, that’s it… for now.
As I mentioned earlier, articles on analyzing robots.txt files aren’t particularly new.
I like to think that this one was a fresh take though.
It gave us an opportunity to explore some of the history surrounding how the files came to be as well as to really dig into the hidden structure in our dataset.
We also touched on some interesting algorithms and analysis techniques along the way.
What more could you ask for?
And as always, let us know if you’re looking for help with your company’s data challenges! Our team are creative experts in web scraping, data infrastructure, and machine learning. Whatever you’re data goals, we can help you get there!
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.

Performing Efficient Broad Crawls with the AOPIC Algorithm
Learn how to estimate page importance and allocate bandwidth during a broad crawl.

User-Agents — Generating random user agents using Google Analytics and CircleCI
A free dataset and JavaScript library for generating random user agents that are always current.
How F5Bot Slurps All of Reddit
The creator of F5Bot explains in detail how it works, and how it's able to scrape million of Reddit comments per day.
Comments