By Evan Sangaline | August 30, 2018
If you’re in a hurry, you can head straight to the user-agents repository for installation and usage instructions!
While web scraping, it’s usually a good idea to create traffic patterns consistent with those that a human user would produce. This of course means being respectful and rate-limiting requests, but it often also means concealing the fact that the requests have been automated. Doing so helps avoid getting blocked by overzealous DDOS protection services, and allows you to successfully scrape the data that you’re interested in while keeping site operators happy.
Making realistic browsing patterns can get pretty complicated–we’ve previously explained some sophisticated techniques in articles like Making Chrome Headless Undetectable and It Is Not Possible to Detect and Block Chrome Headless.
The Intoli Smart Proxy Service even goes far beyond the methods that those articles describe in order to create browsing patterns that are completely indistinguishable from human users.
These advanced concealment strategies are necessary when scraping data from sites protected by bot-mitigation services like Distil and Incapsula, but they’re not always required when scraping websites that are less aggressive about blocking.
For these more basic websites, using realistic User-Agent headers is sometimes all you need.
The only problem is that there aren’t a lot of great resources out there for generating realistic user agents. You need current analytics data from a high traffic website in order to generate random user agents, and this sort of data is seldom made public. There are a handful of paid solutions out there, but the free lists only offer a limited slice of data and usually become outdated very quickly (you can check out Wikipedia’s Usage share of web browsers article to see this for yourself). The situation with open source libraries for random user agent generation is even worse; they’re typically published once or twice and then never updated.
User agent statistics are only really useful for web scraping when they’re up to date, and the few truncated lists that you find when you Google things like “most common user agents” are generally too limited to apply at scale. The Intoli website gets a pretty healthy amount of traffic–and we’re big fans of open information–so this seemed liked a natural opportunity for us to step in and provide the community with a useful resource for web scraping. Long story short: we used our site analytics data to generate realistic usage statistics, and built a new open-source JavaScript library called user-agents for generating random user agents. This is far from the first open-source library to tackle this problem, but we strongly believe that it fills a void in the available tooling.
A few of the key User-Agents features that set the library apart from existing solutions:
-
The user agent data is always up to date. We update the package daily with new data from the Intoli website.
-
The data not only includes user agent strings, but also the corresponding window.navigator properties like navigator.vendor and navigator.platform. This data is very difficult to come by, and is used extensively by bot-mitigation services to block browsers.
-
The data also includes viewport and screen sizes so that they can also be accurately emulated.
-
The random user agent generation can easily be filtered to restrict the user agents by device type, screen size, browser version, or any other available data.
-
The data is available as a raw compressed JSON file, so that it can be easily used in other programming languages.
The package itself is available on npm, and it can be installed by running the following.
# Or with yarn: `yarn add user-agents`
npm install user-agents
Then basic usage is as simple as
import UserAgent from 'user-agents';
const userAgent = new UserAgent();
// Example output:
// User Agent: "Mozilla/5.0 (Windows NT 6.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36"
console.log(`User Agent: "${userAgent}"`);
which will output a random user agent based on how commonly they’re observed in real user data. More advanced usage can include filtering the user agents based on properties like device category
// Restricts the generated user agents to correspond to mobile devices.
const userAgent = new UserAgent({ deviceCategory: 'mobile' });
or accessing detailed properties on the generated user agent objects. For example, you could access the generated viewport size like this:
const userAgent = userAgents.random();
// Example output: 800x600
console.log(`${userAgent.viewportWidth}x${userAgent.viewportHeight}`);
More details on usage and the API are available in the User-Agents repository on GitHub. That’s a good place to start if you’re interested in using User-Agents in your web scraping project. Also be sure to star the repository while you’re over there; it lets us know that people use the project and encourages us to devote more developer resources towards it!
In the rest of this article, we’ll explain how we keep the User-Agents data up to date. The basic idea is that we run a scheduled build on CircleCI every night that fetches the data from Google Analytics and digests it into an anonymized form that’s then committed to the repository and published on npm. You don’t need to understand these details in order to use the User-Agents package, but we thought it was interesting enough to share in case people were curious about how it works. We also wanted to be completely transparent about how this data is collected and exactly what it’s used for.
How It Works
Collecting the data
Like many websites, we use Google Analytics to monitor traffic on our site. Google Analytics tracks a variety of dimensions by default, but the browser user agent isn’t one of them. It breaks this information up into separate quantities like the name of the browser, the version of the browser, etc. In order to track the user agent directly, we needed to add a custom dimension to our analytics.
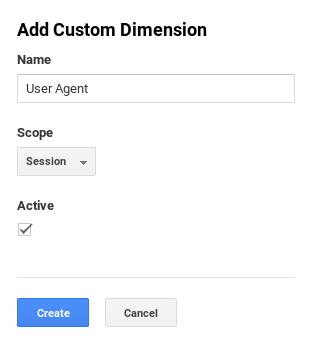
You can see here that we set the dimension to be session-scoped so that the user agent data would be weighted by visitors to the site rather than pageviews. To start actually collecting this data, we simply needed to use the Google Analytics set command to specify that the user agent is equal to the value of the navigator.userAgent property.
ga('set', 'dimension1', navigator.userAgent);
We also added additional custom dimensions for related quantities like navigator.appName, but we we’ll skip over these in the code examples for brevity. Note that we only use these quantities to generate anonymized data for inclusion in the User-Agents package. If you would like to prevent analytics services from collecting this sort of information, then we highly recommend installing uBlock Origin in your browser to block tracking. It also blocks ads and malware, so it’s a useful extension all around.
Configuring API Access to the Raw Data
After we started tracking the data, we needed to be able to access it via an API so that we could automate the process of updating the User-Agents package. Google has a concept of service accounts which can be used to allow exactly this sort of access. To configure this, we first created a new project called “User-Agents NPM Package” on Google’s service accounts page
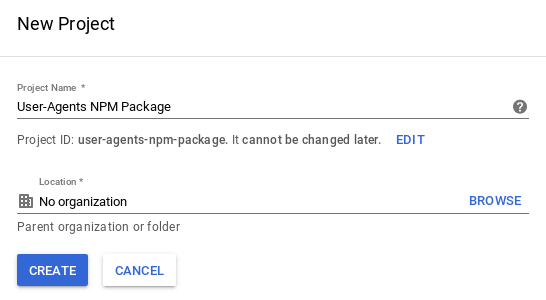
and then enabled the Google Analytics Reporting API for the project.
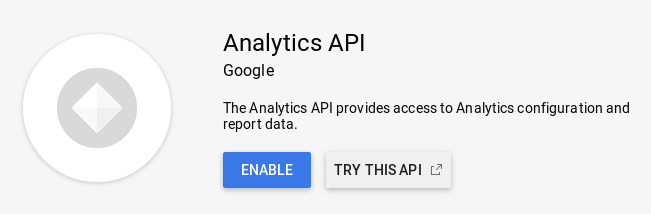
Note that we enabled version 3 of the API rather than the newer version 4, so that we could use the handy ga-api package for authenticating and accessing the API. We’ll come back to that later after we finish setting up the service account and access credentials.
Next, we added a set of credentials to the project, and created a service account in the process.

This generated a JSON credential file for the project that we downloaded and saved as google-analytics-credentials.json.
The JSON credentials are what we use to authenticate with the analytics API, and their contents look something like this.
{
"type": "service_account",
"project_id": "user-agents-npm-package",
"private_key_id": "99f45b8c31520345ab960f17add21da91fc7d2b5",
"private_key": "-----BEGIN PRIVATE KEY-----[REDACTED]-----END PRIVATE KEY-----",
"client_email": "user-agents-npm-package-update@user-agents-npm-package.iam.gserviceaccount.com",
"client_id": "118408973529835432350",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/metadata/x509/user-agents-npm-package-update%40user-agents-npm-package.iam.gserviceaccount.com"
}
The client_email field is of particular interest here; it’s a unique email address that has been assigned to the service account.
As a final step, we needed to create a Google Analytics user for this email address that had read-access to our analytics property.
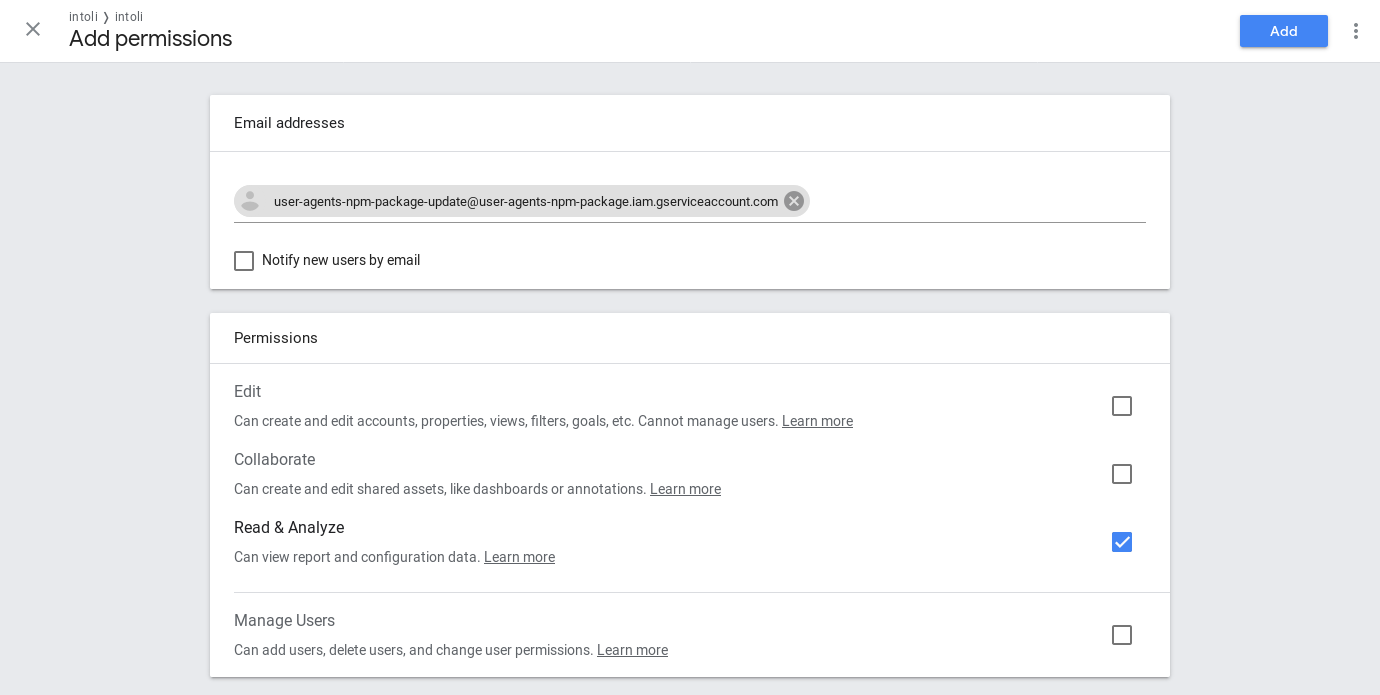
With this last piece in place, we were ready to start accessing the API and looking at real data.
Updating the Project Data
The ga-api JavaScript package is a light wrapper around the Google Analytics API that simplifies the process of authenticating and making requests.
It can be installed using npm or yarn by running the following.
# Or with yarn: `yarn add ga-api@0.0.4`
npm install ga-api@0.0.4
Note that I’ve included an exact version here because I’m a bit weary of passing credentials to a third-party library, but I’ve personally reviewed the code for the v0.0.4 release and know that it’s safe.
Using the library is fairly straightforward and well-documented in the project’s README. As a quick example, the following code queries the analytics property and output rows of data showing the count of sessions for each observed user agent.
const gaApi = require('ga-api');
const accountOptions = {
clientId: 'user-agents-npm-package-update.apps.googleusercontent.com',
email: 'user-agents-npm-package-update@user-agents-npm-package.iam.gserviceaccount.com',
key: 'google-analytics-credentials.json',
ids: 'ga:115995502',
};
const queryOptions = {
startDate: '2018-08-26',
endDate: '2018-08-26',
dimensions: 'ga:deviceCategory,ga:dimension9',
metrics: 'ga:sessions',
};
gaApi({ ...accountOptions, ...queryOptions }, (error, data) => {
if (error) {
console.error(error);
} else {
console.log(data.rows);
}
});
It outputs something similar to the following when run.
[
[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36",
"8356"
],
[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36",
"7311"
],
[
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko/20100101 Firefox/61.0",
"6908"
],
[
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/11.1.2 Safari/605.1.15",
"5921"
],
["// And so on..."]
]
Given this raw data, we simply needed to save it into a JSON file that can be used by the user-agent package to generate random user agents.
The exact details of this are a bit more complicated than the example given here, but you can check out the real code in update-data.js and the real data in user-agents.json.gz if you would like to see the full implementation.
Releasing New Versions Automatically
The major issue with existing user agent generation libraries is that they’re all woefully out of date. The random-user-agent and random-useragent JavaScript packages were both updated two years ago. Even the purportedly always-up-to-date fake-useragent Python package was last updated six months ago. There are literally dozens of other similar projects out there that have all apparently abandoned. It’s understandable that a project’s author would lose interest in manually updating a package like this regularly, and that’s exactly why we thought that an automated release process was so important for the User-Agents package.
We use CircleCI as our continuous integration provider, and they conveniently provide a built-in mechanism to perform scheduled builds.
You can check out the user-agent project’s full config.yml configuration file for all of the details, but we’ll also walk through the general idea here.
To start with, there’s a CircleCI job that handles updating the data.
update:
<<: *defaults
steps:
- attach_workspace:
at: ~/user-agents
- restore_cache:
key: dependency-cache-{{ checksum "yarn.lock" }}
- run:
name: Update the user agents data
command: |
echo "$GOOGLE_ANALYTICS_CREDENTIALS" | base64 --decode > ./google-analytics-credentials.json
yarn update-data
- persist_to_workspace:
root: ~/user-agents
paths:
<<: *whitelist
The update-data script that is run here basically corresponds to a more complicated version of the script that we developed in the last section.
Before we actually run the update-data script, we first populate the google-analytics-credentials.json file that is required to access the raw data from the Google Analytics API.
echo "$GOOGLE_ANALYTICS_CREDENTIALS" | base64 --decode > ./google-analytics-credentials.json
In order to make this work, we first base64 encoded the credentials by running
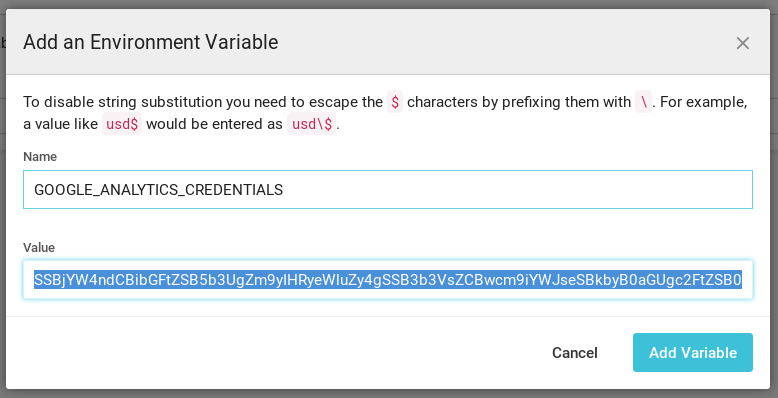
base64 --wrap 0 google-analytics-credentials.json
and then added the contents to the CircleCI build environment as an environment variable called GOOGLE_ANALYTICS_CREDENTIALS.
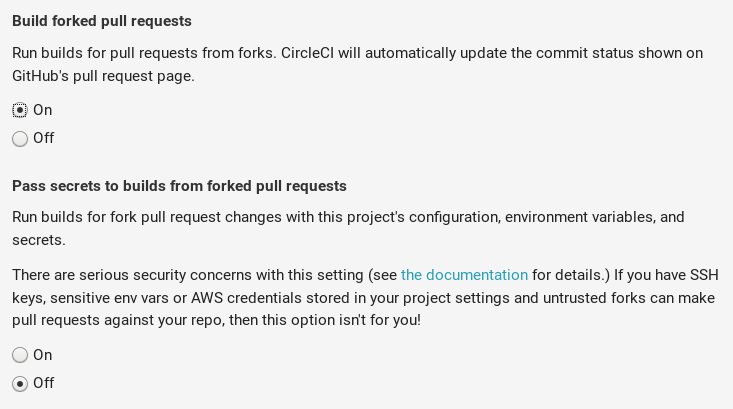
The contents of this environment variable is obviously sensitive, so we also disable providing secrets to forked builds in the CircleCI project settings. Not doing so is a common configuration error that can lead to credentials getting stolen.
Next, there’s a publish-new-version job that commits the updated data to the repository and pushes up the changes to GitHub.
publish-new-version:
<<: *defaults
steps:
- attach_workspace:
at: ~/user-agents
- run:
name: Commit the newly downloaded data
command: |
git add src/*
# Configure some identity details for the machine deployment account.
git config --global user.email "user-agents@intoli.com"
git config --global user.name "User Agents"
git config --global push.default "simple"
# Disable strict host checking.
mkdir -p ~/.ssh/
echo -e "Host github.com\n\tStrictHostKeyChecking no\n" >> ~/.ssh/config
# The status code will be 1 if there are no changes,
# but we want to publish anyway to stay on a regular schedule.
git commit -m 'Regularly scheduled user agent data update.' || true
- run:
name: Bump the patch version and trigger a new release
command: npm version patch && git push && git push --tags
In order to provide write access to the repository, we created a GitHub machine user called user-agents with the appropriate collaborator access.
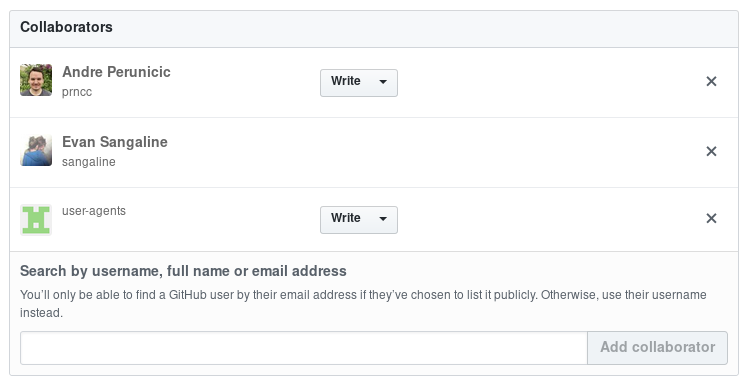
We generated an SSH key for this machine user’s account, and specified in the CircleCI UI that the build should use this write-access key instead of the default checkout key.
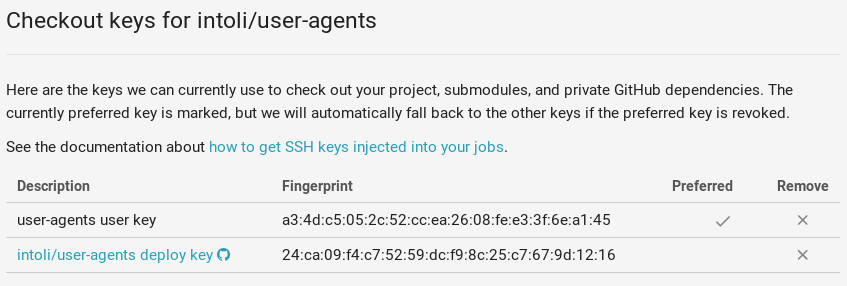
With this in place, the publish-new-version job was able to commit the updated data, create a new patch version for the project, and push up the changes to GitHub.
Pushing these changes, however, doesn’t automatically publish a new version on NPM.
To allow automatically publishing new package versions, we added an additional CircleCI job called deploy.
deploy:
<<: *defaults
steps:
- attach_workspace:
at: ~/user-agents
- run:
name: Write NPM Token to ~/.npmrc
command: echo "//registry.npmjs.org/:_authToken=$NPM_TOKEN" >> ~/.npmrc
- run:
name: Install dot-json package
command: npm install dot-json
- run:
name: Write version to package.json
command: $(yarn bin)/dot-json package.json version ${CIRCLE_TAG:1}
- run:
name: Publish to NPM
command: npm publish --access=public
The logic here is fairly simple:
-
We populate the
~.npmrcfile with an NPM authorization token that’s stored in anNPM_TOKENenvironment variable in a similar way to how we stored the Google Analytics API credentials inGOOGLE_ANALYTICS_CREDENTIALS. -
We use the dot-json package to update the package version in
package.jsonto match the version tag. Thenpm version patchcommand from thepublish-new-versionjob will create tags likev0.0.2, and this code anticipates those being present in theCIRCLE_TAGenvironment variable (which is added automatically to the environment by CircleCI. -
We publish the new package to NPM using npm publish.
The final piece of the puzzle is to set up the conditions under which these various jobs will run.
We did this by defining two CircleCI workflows in the config.yml file.
workflows:
version: 2
scheduled-release:
triggers:
- schedule:
cron: "00 06 * * *"
filters:
branches:
only:
- master
jobs:
- checkout
- update:
requires:
- checkout
- build:
requires:
- update
- test:
requires:
- build
- publish-new-version:
requires:
- test
release:
jobs:
- checkout:
filters:
tags:
only: /v[0-9]+(\.[0-9]+)*/
branches:
ignore: /.*/
- build:
filters:
tags:
only: /v[0-9]+(\.[0-9]+)*/
branches:
ignore: /.*/
requires:
- checkout
- test:
filters:
tags:
only: /v[0-9]+(\.[0-9]+)*/
branches:
ignore: /.*/
requires:
- build
- deploy:
filters:
tags:
only: /v[0-9]+(\.[0-9]+)*/
branches:
ignore: /.*/
requires:
- test
The scheduled-release workflow is configured to be run on a cron schedule at 6 AM everyday.
It runs a sequence of jobs: checkout, update, build, and then test.
We only covered the update job above, but the others are fairly self-explanatory: checkout checks out the code from the repository, build builds the project, and test runs the project tests.
Finally, we define a release workflow that runs the checkout, build, test, and deploy jobs.
The key here is that the jobs in this workflow only run when there’s a new git tag matching the /v[0-9]+(\.[0-9]+)*/ regular expression.
This condition will be met both when we run npm version locally, and when its run in the scheduled-release workflow’s update job.
This allows us to publish things manually while allowing the automated releases to run on a daily basis.
Conclusion
Well, we hope that you’ve enjoyed learning about how we keep the User Agents package consistently up to date. Automation is the key, and both the user-agents GitHub repository and the user-agents NPM package are updated every morning like clockwork. This means that when we say “always up to date,” we mean it!
If your web scraping tasks are still getting blocked when using random user agents, then be sure to check out the Intoli Smart Proxy Service. It integrates all of the web-scraping best-practices that we’ve learned over the years, and it works with pretty much any web scraping software that you might be using.
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.

Performing Efficient Broad Crawls with the AOPIC Algorithm
Learn how to estimate page importance and allocate bandwidth during a broad crawl.
How F5Bot Slurps All of Reddit
The creator of F5Bot explains in detail how it works, and how it's able to scrape million of Reddit comments per day.

No API Is the Best API — The elegant power of Power Assert
A look at what makes power-assert our favorite JavaScript assertion library, and an interview with the project's author.
Comments