By Evan Sangaline | January 18, 2018
A few months back, I wrote a popular article called Making Chrome Headless Undetectable in response to one called Detecting Chrome Headless by Antione Vastel. The one thing that I was really trying to get across in writing that is that blocking site visitors based on browser fingerprinting is an extremely user-hostile practice. There are simply so many variations in browser configurations that you’re inevitably going to end up blocking non-automated access to your website, and–on top of that–you’re really not accomplishing anything in terms of blocking sophisticated web scrapers. To illustrate this, I showed how to bypass all of the suggested “tests” in Antione’s first post and pointed out that they hadn’t been tested in multiple browser versions and would fail for any users with beta or unstable Chrome builds.
Those beta and unstable versions have since become stable versions, and Antione has released an updated version of his blogpost called It is possible to detect and block Chrome headless where he removed the tests that I pointed out as being version dependent and added some new ones. As you might have guessed from the title of this post, I would tend to disagree with the title of his. To clarify: I don’t think it’s possible to detect browser automation for users who are trying to hide it, and if they aren’t trying to hide it then it’s trivial.
There’s a window.navigator.webdriver property defined as part of the WebDriver spec that’s meant to indicate when WebDriver is being used, but it was implemented in Chrome as an indication of any browser automation.
The summary of the property from the Chrome Intent to Ship is the following.
Add enumerable, non-configurable, readonly property
webdriverto navigator object of a window global object. Property istrueif CommandLine has either “enable-automation“ or “headless“ switch. Otherwise isfalse.
So basically, const isAutomated = navigator.webdriver; is your headless test (OK, that’s really testing for automated rather than headless browsers, but that’s generally what people are actually trying to do anyway).
As soon as you go beyond that, you’re basically indicating that you’re trying to detect users who are actively hiding the fact that their browser is automated.
That’s when it becomes impossible.
You can come up with whatever tests you want, but any dedicated web scraper can easily get around them.
If you’ve read Making Chrome Headless Undetectable, then this article should be pretty familiar. I’ll set up a test page that implements each of Antione’s tests, and then show how it’s fairly trivial to bypass each of them. I used Selenium last time, so this time I’ll use Puppeteer to spice it up. Most of the test bypasses are implemented as injected JavaScript however, so much of the code should be applicable to any browser automation framework that supports JavaScript injection (see: JavaScript Injection with Selenium, Puppeteer, and Marionette). All of the code developed here–and instructions for running it–is also available on GitHub. Feel free to grab that first if you would like to experiment with the code and run things as you read along here.
Performing the Tests
I implemented each of the tests that Antione proposes in a simple test page called chrome-headless-test.html. The page renders a simple table like this
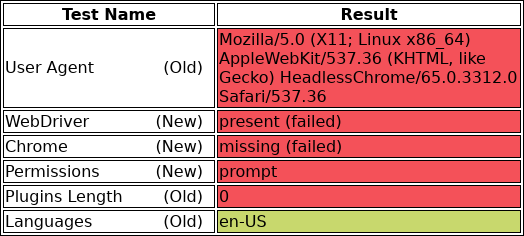
with the results for each test. The actual tests that are used to populate the table when the page loads are in chrome-headless-test.js, but I’ll go over the details of each test when I cover bypassing them. The results shown here are what are produced by a headless browser without any attempt at hiding itself.
As I mentioned earlier, I’ll use Puppeteer as my automation framework throughout the article.
Puppeteer provides a friendly high-level JavaScript API built on top of the Chrome DevTools Protocol, and it’s one of my favorite automation frameworks to work with.
It can be installed by running yarn install puppeteer and it will download it’s own Chromium build inside of node_modules to use during automation.
The code to visit the test page and record the test results with Puppeteer is quite simple. We basically just launch the browser in headless mode, visit the test page, take a screenshot of the results table, and exit. The code for doing this is available in test-headless-initial.js, and its contents are as follows.
// We'll use Puppeteer is our browser automation framework.
const puppeteer = require('puppeteer');
// This is where we'll put the code to get around the tests.
const preparePageForTests = async (page) => {
// TODO: Not implemented yet.
}
(async () => {
// Launch the browser in headless mode and set up a page.
const browser = await puppeteer.launch({
args: ['--no-sandbox'],
headless: true,
});
const page = await browser.newPage();
// Prepare for the tests (not yet implemented).
await preparePageForTests(page);
// Navigate to the page that will perform the tests.
const testUrl = 'https://intoli.com/blog/' +
'not-possible-to-block-chrome-headless/chrome-headless-test.html';
await page.goto(testUrl);
// Save a screenshot of the results.
await page.screenshot({path: 'headless-test-result.png'});
// Clean up.
await browser.close()
})();
This can be run with node test-headless-initial.js and it will produce a headless-test-results.png file with the results table that we saw earlier.
You’ll notice that there’s a preparePageForTests method defined at the top of the file that currently does nothing.
Throughout the rest of this article, we’ll go through the tests one by one and show how to bypass them.
The final result is available in test-headless-final.js if you want to take a look at all of the code together at once.
Bypassing the Tests
Let’s just go through and bypass each of these tests one-by-one now.
Keep in mind that all of the code developed in each of these sections is intended to go inside of the preparePageForTests method that is called before visiting the test page.
This means that the page object is available and we’re inside of an async function (so we can use await).
If you get confused about how any of the parts fit together, just look inside of test-headless-final.js.
The User-Agent Test
// User-Agent Test
if (/HeadlessChrome/.test(navigator.userAgent)) {
// Test Failed...
}
This is the classic test of automated access which has been around since long before headless browsers or even browser automation frameworks (for server-side checks at least).
It has a relatively low false postive rate, but it’s also the most trivial thing to spoof or bypass.
Command-line tools like curl and wget provide flags to change the User-Agent header, and Chrome is no different.
You can specify the --user-agent flag when launching Chrome–headless or otherwise–and it will modify both the User-Agent header and the navigator.userAgent object.
Puppeteer also provides a setUserAgent() method that can be used to accomplish the same thing. All it takes is adding
// Pass the User-Agent Test.
const userAgent = 'Mozilla/5.0 (X11; Linux x86_64)' +
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.39 Safari/537.36';
await page.setUserAgent(userAgent);
to our preparePageForTests() method and this test is passed.
The Webdriver Test
// Webdriver Test
if (navigator.webdriver) {
// Test Failed...
}
This is an interesting test for a couple of reasons.
It’s the only other test that will have a relatively low false positive rate for one thing (although there are accessibility tools which rely on browser automation).
Additionally, you see some odd behavior if you attempt to set navigator.webdriver = false as a way to bypass the test.
You don’t get an error during assignment, but navigator.webdriver will still be true afterwards.
To get around this, we need to use Object.defineProperty() to redefine the webdriver property on navigator using a new getter function.
Here’s an example of doing this interactively in the Chrome DevTools.
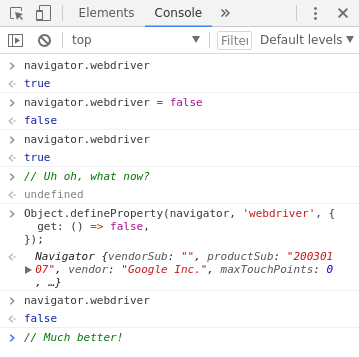
The relevant bit of code to add to our preparePageForTests() method is
// Pass the Webdriver Test.
await page.evaluateOnNewDocument(() => {
Object.defineProperty(navigator, 'webdriver', {
get: () => false,
});
});
and it brings us one step closer to straight As on our totally-not-headless exam. Notice that we’re using Puppeteer’s evaluateOnNewDocument() method to ensure that our property is redefined in the page context before any of the page’s JavaScript can running. We’ll be using this same method in all of our other tests as well. You can find more details about it–and similar methods for other browser automation frameworks–in our JavaScript Injection with Selenium, Puppeteer, and Marionette article.
The Chrome Test
// Chrome Test
if (!window.chrome) {
// Test Failed...
}
Google Chrome doesn’t currently support extensions, and the window.chrome object is undefined in headless mode (NOTE: I was mistaken about the property not being undefined in an earlier version of this article).
In a non-headless browser, the window.chrome object looks something like this (keep in mind that the Web Extensions API is not available in the page context).
{
app: {
isInstalled: false,
},
webstore: {
onInstallStageChanged: {},
onDownloadProgress: {},
},
runtime: {
PlatformOs: {
MAC: 'mac',
WIN: 'win',
ANDROID: 'android',
CROS: 'cros',
LINUX: 'linux',
OPENBSD: 'openbsd',
},
PlatformArch: {
ARM: 'arm',
X86_32: 'x86-32',
X86_64: 'x86-64',
},
PlatformNaclArch: {
ARM: 'arm',
X86_32: 'x86-32',
X86_64: 'x86-64',
},
RequestUpdateCheckStatus: {
THROTTLED: 'throttled',
NO_UPDATE: 'no_update',
UPDATE_AVAILABLE: 'update_available',
},
OnInstalledReason: {
INSTALL: 'install',
UPDATE: 'update',
CHROME_UPDATE: 'chrome_update',
SHARED_MODULE_UPDATE: 'shared_module_update',
},
OnRestartRequiredReason: {
APP_UPDATE: 'app_update',
OS_UPDATE: 'os_update',
PERIODIC: 'periodic',
},
},
}
Based on this, a more sophisticated test could dig into the structure of the chrome object.
// Chrome Test
if (!window.chrome || !window.chrome.runtime) {
// Test Failed...
}
Of course, this is still trivial to bypass. We simply need to mock whatever is being checked for by the test code.
// Pass the Chrome Test.
await page.evaluateOnNewDocument(() => {
// We can mock this in as much depth as we need for the test.
window.navigator.chrome = {
runtime: {},
// etc.
};
});
Pop that in preparePageForTests() and you’re good to go.
The Permissions Test
// Permissions Test
(async () => {
const permissionStatus = await navigator.permissions.query({ name: 'notifications' });
if(Notification.permission === 'denied' && permissionStatus.state === 'prompt') {
// Test Failed...
}
})();
The idea behind this test is that Notification.permission and the results from navigator.permissions.query report contradictory values.
All we need to do to get around this is to make sure that they are consistent.
We can do that by overriding the navigator.permissions.query method with one that behaves how we want it to.
// Pass the Permissions Test.
await page.evaluateOnNewDocument(() => {
const originalQuery = window.navigator.permissions.query;
return window.navigator.permissions.query = (parameters) => (
parameters.name === 'notifications' ?
Promise.resolve({ state: Notification.permission }) :
originalQuery(parameters)
);
});
Note that this will pass through to the original navigator.permissions.query method if the query name isn’t notifications, but other queries can be handled similarly if the tests are more sophisticated.
The Plugins Length Test
// Plugins Length Test
if (navigator.plugins.length === 0) {
pluginsLengthElement.classList.add('failed');
// Test Failed...
}
This is a particularly user-hostile test because the browser plugins are often concealed as a privacy measure.
Firefox does this by default, and there are extensions that provide the same behavior in Chrome.
To spoof the plugins, we can simply define another property getter on navigator like we did for webdriver.
// Pass the Plugins Length Test.
await page.evaluateOnNewDocument(() => {
// Overwrite the `plugins` property to use a custom getter.
Object.defineProperty(navigator, 'plugins', {
// This just needs to have `length > 0` for the current test,
// but we could mock the plugins too if necessary.
get: () => [1, 2, 3, 4, 5],
});
});
The Languages Test
// Languages Test
if (!navigator.languages || navigator.languages.length === 0) {
// Test Failed...
}
Finally, we get to the languages test. This is another test that vanilla headless Chrome passes without issues for me. Without digging too deeply into this, it likely depends on either the operating system or its configuration.
If your configuration doesn’t provide any languages via navigator.languages, you can again defined a property getter like we did with both plugins and webdriver.
// Pass the Languages Test.
await page.evaluateOnNewDocument(() => {
// Overwrite the `plugins` property to use a custom getter.
Object.defineProperty(navigator, 'languages', {
get: () => ['en-US', 'en'],
});
});
That’s the last of the tests, everything should pass at this point. Be sure to check out test-headless-final.js to see how everything fits together or to try running it for yourself.
Putting It All Together
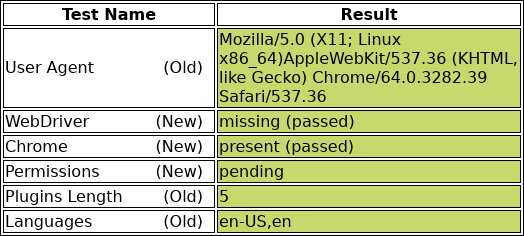
As you can see, we were able to bypass all of these tests without much difficulty at all. The script that we used to bypass these obviously isn’t going to work in all cases, but the techniques are generally applicable and can be customized for any particular set of tests that a site might employ. If somebody wants to conceal the fact that they’re using a browser automation framework on your site, then they’re going to be able to. Blocking users based on browser fingerprinting is generally a bad idea, and one that mostly ends up hurting users.
If you found this article because you’re dealing with some browser automation issues of your own, then please do get in touch. We have a lot of experience with this sort of thing, and we love working on new projects.
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.

Performing Efficient Broad Crawls with the AOPIC Algorithm
Learn how to estimate page importance and allocate bandwidth during a broad crawl.
Breaking Out of the Chrome/WebExtension Sandbox
A short guide to breaking out of the WebExtension content script sandbox.

User-Agents — Generating random user agents using Google Analytics and CircleCI
A free dataset and JavaScript library for generating random user agents that are always current.
Comments