By Evan Sangaline | September 14, 2018
WebExtensions are a frequently underappreciated tool for the purposes of web scraping and browser automation. They provide an easy way to access an extremely powerful API that’s cross browser compatible out of the box, and that API provides functionality that extends far beyond that of more specialized automation APIs like the Chrome DevTools Protocol or Firefox’s Marionnette. For example, the WebExtensions API provides a mechanism for containerizing individual tabs–Selenium and Puppeteer can’t do that!
We’re such big fans of using the WebExtensions API for web scraping here at Intoli that we built a whole web automation framework based on it. We’ve also frequently recommended WebExtensions in our articles as a way to supplement other common browser automation frameworks. Doing so makes it possible to inject JavaScript before page loads, and also allows you to make use of the full privileged WebExtensions API. Recently, a number of people have been emailing us to ask for help when they run into limitations caused by their scripts running in a sandboxed environment. We did our best to answer those questions, but we figured that writing an explicit guide here would be a good idea since it seems like a common problem.
In this guide, we’ll start off by explaining a bit about how WebExtensions work, and how content script sandboxing can lead to unexpected and confusing behavior. Then we’ll develop code that can be used as a drop-in solution for breaking out of the content script sandbox so that code can be run directly in the context of webpages themselves. As always, you can find the finished product in the intoli-article-materials repository on GitHub, so feel free to skip over there if you want to see how all of the pieces fit together in the end. And be sure to star the repo to find out about new articles from the Intoli blog before they’re released!
Understanding the Problem
To give a quick crash course on WebExtensions, they very roughly consist of a variety of JavaScript HTML page contexts and the code that runs in those contexts. You can specify HTML documents and other resources to populate the DOM in those contexts, but that’s mostly tangential to browser automation. The main contexts that you’ll ever work with are the background script context and the content script context.
The background script context is owned completely by your extension and exists as long as your extension is running. It’s sort of like the control center for your extension where you’ll put code that manages state over time and coordinates code in the other contexts. The content script context is a little more complicated.
You specify URL match patterns for your content script code, and then your code will be injected and run in a content script context every time a browser tab navigates to a matching URL. You can access and modify the tab’s DOM in that context, do any of the normal JavaScript stuff that you know and love, and your context will be destroyed when the tab is closed or navigated to another URL. Things generally appear like the code is executing in the page context, but it isn’t.
Part of the reason that I mentioned the background script context first is to contrast it against the content script context. There’s a very clear distinction made between these contexts when you read about them in the WebExtensions documentation, and there are officially sanctioned mechanisms for communicating between them. The runtime.onMessage() and runtime.sendMessage() methods exist solely for the purpose of communicating between different extension contexts, and there’s no ambiguity about this being necessary. In contrast, the line between a context script context and the page context that it corresponds to is blurred and harder to see.
Let’s make this blurry line a little more clear by building a simple extension designed to modify window.navigator properties like we’ve done before in articles like Making Chrome Headless Undetectable and It is not possible to detect and block Chrome headless.
First, create a directory called extension by running
mkdir extension
in your terminal.
Then create an extension/manifest.json file with the following contents.
{
"manifest_version": 2,
"name": "Content Script Sandbox Breakout Extension",
"version": "1.0.0",
"applications": {
"gecko": {
"id": "sandbox-breakout@intoli.com"
}
},
"content_scripts": [
{
"matches": ["<all_urls>"],
"js": ["sandbox-breakout.js"],
"run_at": "document_start"
}
]
}
This manifest file tells web browsers how to load and run our extension.
In particular, the content_scripts entry tells the browser to inject a file called sandbox-breakout.js on every page load that matches any URL at all.
Setting run_at to document_start specifies that the script should be injected as soon as document.readyState is equal to loading.
This ensures that our JavaScript will be evaluated before any of the code on pages that we visit.
Next, create the actual extension/sandbox-breakout.js file with the following contents.
// Overwrite the `navigator.language` property to return a custom value.
const overwriteLanguage = (language) => {
Object.defineProperty(navigator, 'language', {
get: () => language,
});
};
// This won't work, it's sandboxed from the page context.
overwriteLanguage('xx-XX');
This uses the Object.defineProperty() method to change the apparent value of the navigator.language property to xx-XX.
We need to define the property rather than simply assigning to it because it’s ready-only, but the code is otherwise pretty straightforward.
This sort of pattern is extremely common when modifying browser fingerprints to circumvent bot-mitigation systems like Distil and Incapsula.
As you might have figured out from the comments in the code, this won’t work quite as intended.
To see this in action, first create an HTML file called language-test.html with these contents.
<html>
<body>
<h1 id="result">Please Wait...</h1>
<script type="text/javascript">
document.getElementById('result')
.innerHTML = navigator.language;
</script>
</body>
</html>
The page consists of a single header element for displaying the test results and a script tag that populates it with the current value of navigator.language.
This will equal xx-XX if our sandbox-breakout.js script works as expected, but will otherwise equal the actual browser language setting (for me that’s en-US).
We can finally load this test page with the extension preloaded by running this command.
google-chrome --load-extension=./extension/ language-test.html
A browser window should pop up and reveal that the test did indeed fail.
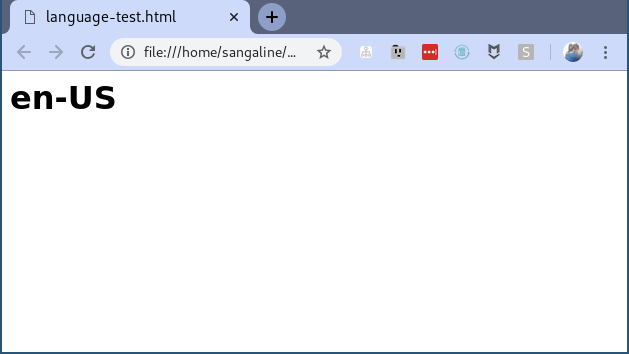
The reason that the test fails isn’t that our overwriteLanguage() method doesn’t overwrite the navigator.language property–it’s that it overwrites the wrong navigator.language property.
The page context is sandboxed from the content script context for security reasons, and that sandboxing isolates the native DOM objects between the contexts.
This isolation exists in all browsers which implement the WebExtensions API, but it’s called Xray Vision in Firefox and they do a good job of explaining the details of the implementation and the reasoning behind it if you want to learn more.
The basic gist is that the content script sandboxing exists to protect content scripts from malicious page code, not the other way around. This is done because content scripts are a privileged execution environment (i.e. they have partial access to the WebExtensions API), and code on a random website could theoretically exploit them to gain access to that environment . That’s a great protection for random browser users who install and use extensions, but it’s a serious annoyance if you’re developing an extension and the sandbox is preventing you from doing something that you want to do. If only there were a way to break out of the sandbox…
Breaking Out of the Sandbox
Content script sandboxing prevents direct modification of JavaScript objects that are part of the DOM, but content scripts are able to call DOM methods which mutate the DOM themselves. For example, a content script is blocked from modifying the behavior of a method like Node.appendChild(), but it can call that method to add a node to the DOM. This means that we can create a script tag, inject it into the page, and the code inside the script tag will be evaluated in that context. That provides a mechanism for content scripts to run arbitrary code in the true page context instead of the isolated content script context.
Let’s look at a full code example first, and then we’ll break it down piece-by-piece.
This code can be added to the end of extension/sandbox-breakout.js in order to allow overwriteLanguage() to execute in the page context so that the test page displays the desired xx-XX result.
// Breaks out of the content script context by injecting a specially
// constructed script tag and injecting it into the page.
const runInPageContext = (method, ...args) => {
// The stringified method which will be parsed as a function object.
const stringifiedMethod = method instanceof Function
? method.toString()
: `() => { ${method} }`;
// The stringified arguments for the method as JS code that will reconstruct the array.
const stringifiedArgs = JSON.stringify(args);
// The full content of the script tag.
const scriptContent = `
// Parse and run the method with its arguments.
(${stringifiedMethod})(...${stringifiedArgs});
// Remove the script element to cover our tracks.
document.currentScript.parentElement
.removeChild(document.currentScript);
`;
// Create a script tag and inject it into the document.
const scriptElement = document.createElement('script');
scriptElement.innerHTML = scriptContent;
document.documentElement.prepend(scriptElement);
};
// Break out of the sandbox and run `overwriteLanguage()` in the page context.
runInPageContext(overwriteLanguage, 'xx-XX');
You can see here that we’re passing in the overwriteLanguage() function object as a variable called method and the desired language as an array called args.
We now need to translate these into a string that we’re able to to inject as a script tag, something which will require a bit of massaging so that things are serialized just right.
Starting with the method itself, we first check whether method is actually a function or a string (which would correspond to manually stringified JavaScript code).
We use Function.toString() to return the source code of the method if it’s a function, and otherwise wrap any literal code in an arrow function by using a template literal.
The code example above will always pass in an actual function, but it’s nice to support strings too so that you can use runInPageContext('alert("Hi!")') as a shorthand for runInPageContext(() => { alert('Hi!'); }).
This is just a convenience for readers who would like to use runInPageContext() in their own projects.
Converting a function into a string was pretty easy because we were able to use the built-in Function.toString() method, but an important point here is that this doesn’t handle the closure context in a graceful way.
If method were to rely on some variable from the lexical scope where the function was defined, then it would simply be undefined when we tried to evaluate the function source code in another scope (or browser context!).
That’s part of the motivation behind passing the arguments separately to the runInPageContext() method; it allows us to include variables from a local context without using closures (because those wouldn’t work).
To stringify the arguments themselves, we use the JSON.stringify() method to convert the array into its JSON string representation.
So if args is an array instance equal to [ 'xx-XX' ], then JSON.stringify(args) will be a string equal to ["xx-XX"].
This string will then be reconstructed into an actual array when it’s encountered by the JavaScript interpreter in our script tag.
An explicit call to JSON.parse() isn’t required because we’re basically using an implicit eval() in its place.
const array = ['xx-XX'];
const stringifiedArray = JSON.stringify(array);
// The values of `evaledStringifiedArray` and `array` are the same.
const evaledStringifiedArray = eval(stringifiedArray);
JSON isn’t actually a true subset of JavaScript, but this would only be an issue if the string were to contain very specific and uncommon unicode characters.
Stringifying the method and arguments such that they can be interpreted as JavaScript code is really the only tricky part of constructing our script contents. We then simply wrap the function in some parenthesis and invoke it with the arguments passed to the function using the spread operator.
For good measure, we also add some hardcoded JavaScript that removes the code’s containing script tag.
// Remove the script element to cover our tracks.
document.currentScript.parentElement
.removeChild(document.currentScript);
This isn’t strictly necessary, but it makes it impossible for code in the webpage to figure out that we’ve made modifications to the DOM.
Finally, we just need to actually create a script tag using document.createElement() and inject it into the page.
// Create a script tag and inject it into the document.
const scriptElement = document.createElement('script');
scriptElement.innerHTML = scriptContent;
document.documentElement.prepend(scriptElement);
Our specially crafted script content will be evaluated as soon as the script is injected, and then immediately removed before any code in the webpage has a chance to run.
If we run Chrome with our extension preloaded again, we’ll now see the desired xx-XX result.
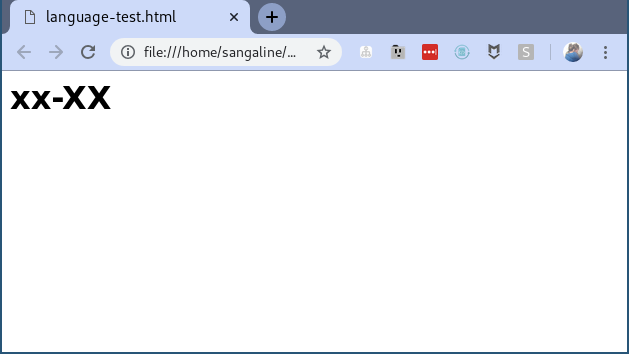
This particular test is a bit simplistic, but you can use this same approach for far more advanced DOM manipulations and bot-mitigation strategies. That’s exactly what we do in the Intoli Smart Proxy service in order to make it easy for our users to scrape data without having to worry about blocking. If this is something that you’re struggling with, then you should definitely get in touch.
Wrap Up
You hopefully now understand how to break out of the content script sandbox in an extension.
It’s probably more accurate to call this breaking in to the sandbox because we went from the more privileged environment to the less privileged one, but it can still be a frustrating barrier when you’re trying to access portions of the DOM from a browser extension.
I tried to make the runInPageContext() method fairly general, so it should be easy to reuse in your own projects.
You can find the finished version over in the intoli-article-materials repository along with some more usage information.
I’ll also mention that the sort of techniques that were laid out in this article are heavily inspired by the Remote Browser automation framework. The framework is built on the power of the WebExtensions API, and it strives to make it as easy as possible to evaluate code in different contexts while staying mostly out of your way. If you’re interested in both WebExtensions and browser automation, then you should definitely check it out.
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.
Building a YouTube MP3 Downloader with Exodus, FFmpeg, and AWS Lambda
A short guide to building a practical YouTube MP3 downloader bookmarklet using Amazon Lambda.
Running FFmpeg on AWS Lambda for 1.9% the cost of AWS Elastic Transcoder
A guide to building a transcoder using Exodus, FFmpeg, and AWS Lambda.
Extending CircleCI's API with a Custom Microservice on AWS Lambda
A guide to setting up a practical proxy API on Amazon's Lambda using Node.js and Express.
Comments