By Evan Sangaline | May 21, 2018
Let’s focus on the easy part first: what we’ll be building in this tutorial. The end result will be a browser bookmarklet which can be used to convert YouTube videos to MP3s and download them. The basic interaction flow is that you click on the bookmarklet while on the page for a specific video, a new tab opens and displays a progress bar for the conversion, and then the download starts automatically as soon as it’s ready. You can see it in action here.
One of the more difficult aspects of making this work is transcoding the content to an MP3 format on Lambda, which we covered in the first part of this tutorial. This second installment of the series will cover building an Express backend for the bookmarklet and the process of deploying it using AWS Lamda and AWS API Gateway. Note that we’ll be picking things up exactly where the last article left off; we’ll assume that you have already created the roles, policies, and the transcoding Lambda function from that first part. If you stumbled upon this without having read that transcoding tutorial first, then you’ll probably want to go check it out in order to better understand the context of these instructions.
We’ll go through the process of building everything up step-by-step here, but all of the finished code is also available in the intoli-article-materials repository. Feel free to browse through there at any point to get a better idea of how everything fits together. Starring that repository is also a great way to find out about new content from Intoli, because we post supplementary materials there for all of our new technical articles. Now that that’s out of the way, let’s get building!
The Backend API
Whenever my intention is to eventually deploy a simple API on AWS Lambda, I like to start out by prototyping it locally using Express. It offers easy routing, a robust middleware ecosystem, templating integrations, and more out of the box–all while being relatively lightweight. That stuff is all awesome, but it’s also just really convenient being able to run an API on your local machine during development without needing to worry about emulating a full Lambda environment. This is the pattern that we’ll follow while developing the YouTube MP3 downloader backend; we’ll first build the entire app locally using Express, and then move on to integrating with Lambda after we have everything working.
Before we get started, note that you can either create a new working directory for the YouTube MP3 downloader project, or continue working in the same directory that you used during the media transcoder tutorial.
The only downside of sharing the directory is that there will be a few extra dependencies in node_modules which are only needed by one of the two Lambda functions.
This might be a big deal if one of our functions was close to the 250 GB limit, but that isn’t the case here so either way is fine.
Dependencies and Configuration
Now, let’s start off by installing the dependencies for our project. We’ll eventually need the aws-sdk for interacting with AWS S3 and the transcoding Lambda function, express to use as our web framework, nunjucks for templating, and ytdl-core for finding meta-information about YouTube videos. These can all be installed in one fell swoop using Yarn.
yarn add aws-sdk express nunjucks ytdl-core
After these finish installing, we can begin actually writing our API.
We’ll be putting everything in a single file called app.js in the root of our directory.
Each chunk of JavaScript code that we look at here should be appended to that file sequentially.
You can also see a full copy of the file here, if it’s ever not clear exactly how things fit together.
At the top of the app.js file, we’ll start out by importing each of the libraries that we just installed.
const AWS = require('aws-sdk');
const express = require('express');
const nunjucks = require('nunjucks');
const ytdl = require('ytdl-core');
Then we’ll create a few global variables which configure the details of how we’ll interact with S3 and the transcoding Lambda function.
// Global configuration variables.
const apiStage = 'v1';
const transcoderFunctionName = 'YoutubeMp3TranscoderFunction';
const s3Bucket = 'youtube-mp3-downloader';
// AWS SDK objects for interacting with Lambda and S3.
const lambda = new AWS.Lambda({ region: 'us-east-2' });
const s3 = new AWS.S3({ signatureVersion: 'v4' });
The apiStage variable is just an arbitrary value that we’ll use to prefix our API routes.
You don’t have to worry too much about that right now; we’ll come back to it when we actually use it.
Beyond that, you’ll need to set the transcoderFunctionName and s3Bucket variables to match the names that you used in the first part of this tutorial.
Additionally, the region that you specify while initializing the AWS.Lambda instance will need to be the same one where the transcoder function was deployed.
For some reason, the AWS nodejs SDK only parses ~/.aws/credentials and not ~/.aws/config, so this is the one place where we have to explicitly specify our default region.
Next we’ll initialize our express route, configure it to use Nunjucks for templating, and create a router to use for our routes.
// Initialize the Express app and a router instance.
const app = express();
const router = express.Router();
// Use the current directory as the template root.
nunjucks.configure('.', { express: app });
We’ll assume that you have some basic familiarity with Express as we move forward, but if not you should take a look at their getting started page. Don’t worry if you haven’t used Nunjucks before though; it’s just a nice templating engine from Mozilla that’s heavily inspired by jinja2. We’ll just be using it for basic variable substitution in the page that the bookmarklet opens, and the syntax is dead simple.
The Transcoding Route
With the basic configuration out of the way, we can get started on our first route: the transcoding route. This API endpoint will take in a YouTube video ID, construct a Lambda event object for the MP3 conversion, and then invoke our transcoding Lambda function asynchronously. The endpoint will then return a JSON response containing the S3 keys where the resulting MP3 and log files will be placed. These keys will be used later to check on the status of the transcoding process.
As a quick reminder, the transcoding function from the first part of this tutorial expects an event object containing the following parameters.
filename- The filename to use when downloading the MP3 from S3.logKey- The S3 key where the FFmpeg output will be logged.mp3Key- The S3 key where the transcoded MP3 will be stored.s3Bucket- The S3 bucket where the MP3 and log files will be stored.url- The URL from which the source media can be downloaded.
The s3Bucket is just a configuration setting, but the rest of these will depend on the details of each specific YouTube video that we transcode.
The url parameter will have to point to a media file on YouTube’s server, and we’ll also want to include the video’s title in the filename, logKey, and mp3Key parameters.
Luckily, there’s an awesome ytdl-core library which makes it really easy to find this sort of information for YouTube videos.
The ytdl-core library has a getInfo() method which returns a lot of information about a YouTube video.
There’s an example response included in the ytdl-core repository, but you can also copy and paste the following into the node repl in order to generate a response yourself.
const ytdl = require('ytdl-core');
// Construct the video URL from the video ID.
const videoId = 'DcxxPtWAm7c';
const videoUrl = `https://youtube.com/watch?v=${videoId}`;
// Get the meta-information for the video and print it out.
ytdl.getInfo(videoUrl, (error, info) => {
console.log(JSON.stringify(info, null, 2));
});
The only two things that we really care about here are the video title and the URL where it can be downloaded.
The title is accessible in info.title, but getting a download URL is a little more complicated.
The getInfo() response will include an info.formats array containing information about dozens of different media encodings for the video.
Each entry in the array consists of an object which includes information like the encoding’s download URL, format, bitrate, container. etc.
Here’s an example of the object representing a VP9 encoding of the video we queried above.
{
"clen": "2091047",
"init": "0-243",
"itag": "242",
"fps": "30",
"lmt": "1515737291461881",
"url": "https://r6---sn-p5qs7nes.googlevideo.com/videoplayback?initcwndbps=608750&ei=CeTIWtzwBsLHqgXW2ryQBg&dur=139.372&expire=1523136617&sparams=aitags%2Cclen%2Cdur%2Cei%2Cgir%2Cid%2Cinitcwndbps%2Cip%2Cipbits%2Citag%2Ckeepalive%2Clmt%2Cmime%2Cmm%2Cmn%2Cms%2Cmv%2Cpl%2Crequiressl%2Csource%2Cexpire&mv=m&aitags=133%2C134%2C135%2C136%2C160%2C242%2C243%2C244%2C247%2C278%2C298%2C302&source=youtube&clen=2091047&c=WEB&signature=81779A75F18070C50D3FE5E42973B3DCF7F41A2F.D74F6AB7CC06CC6AD1D607FA61B692C7B1EE45EF&fvip=6&key=yt6&lmt=1515737291461881&keepalive=yes&itag=242&ipbits=0&mm=31%2C29&mn=sn-p5qs7nes%2Csn-hp57kn67&id=o-ADaLus_W0qTdBgR_fwu9pUR-u6N_uqiNSIgHZ9BV7YbG&mime=video%2Fwebm&pl=16&mt=1523114926&gir=yes&ms=au%2Crdu&ip=71.214.192.216&requiressl=yes&ratebypass=yes",
"xtags": "",
"primaries": "bt709",
"quality_label": "240p",
"projection_type": "1",
"size": "426x240",
"index": "244-709",
"type": "video/webm; codecs=\"vp9\"",
"bitrate": "0.1-0.2",
"eotf": "bt709",
"container": "webm",
"resolution": "240p",
"encoding": "VP9",
"profile": "profile 0",
"audioEncoding": null,
"audioBitrate": null
}
We can grab the url parameter from any one of these format objects to pass on to our transcoding function, but which one should we choose?
Although any format should work as an input to FFmpeg, we can significantly cut down on the download time by choosing an audio only encoding.
We’ll select those by requiring that audioEncoding isn’t null, and then choose the largest available input file (which will tend to correspond to higher quality formats).
Putting this all together, we can construct our first API route and add it to app.js.
router.get('/transcode/:videoId', (req, res) => {
const timestamp = Date.now().toString();
const { videoId } = req.params;
const videoUrl = `https://www.youtube.com/watch?v=${videoId}`;
// Get information on the available video file formats.
Promise.resolve().then(() => new Promise((resolve, revoke) => {
ytdl.getInfo(videoUrl, (error, info) => error ? revoke(error) : resolve(info))
}))
// Choose the best format and construct the Lambda event.
.then(({ formats, title }) => {
// We'll just pick the largest audio source file size for simplicity here,
// you could prioritize things based on bitrate, file format, etc. if you wanted to.
const format = formats
.filter(format => format.audioEncoding != null)
.filter(format => format.clen != null)
.sort((a, b) => parseInt(b.clen, 10) - parseInt(a.clen, 10))[0];
return {
filename: `${title}.mp3`,
logKey: `log/${timestamp} - ${title}.log`,
mp3Key: `mp3/${timestamp} - ${title}.mp3`,
s3Bucket,
url: format.url,
};
})
// Trigger the actual conversion in the other Lambda function.
.then(lambdaEvent => new Promise((resolve, revoke) => {
lambda.invoke({
FunctionName: transcoderFunctionName,
InvocationType: 'Event',
Payload: JSON.stringify(lambdaEvent),
}, (error, data) => error ? revoke(error) : resolve(lambdaEvent));
}))
// Send a response
.then(({ logKey, mp3Key }) => {
res.status(200).send(JSON.stringify({ logKey, mp3Key }));
})
// Handle errors.
.catch((error) => {
return res.status(500).send(`Something went wrong: ${error.message}`);
});
});
Aside from the querying and parsing of the video information, you can see that we’re mainly just constructing the lambdaEvent object and then invoking our transcoding function with a call to AWS.Lambda.invoke().
There’s nothing too fancy here, the S3 keys for the MP3 and log files are just constructed using a combination of the current timestamp and the video title to ensure that they’re unique.
These keys are then included in the route’s JSON response so that they can–as we’ll see in a minute–be used to check on the transcoding status.
The Signed URL Route
A simplified version of our YouTube MP3 downloader could simply trigger these asynchronous transcoding tasks, and leave it to the user to browse and download things from S3. The MP3 files are meaningfully named, so browsing from the AWS S3 web console actually wouldn’t be so bad at all.
That said, it adds a nice bit of polish for our bookmarklet to be able to automatically trigger the downloads once they’re ready, and this is actually pretty easy to accomplish.
Our transcoding Lambda function won’t upload the FFmpeg log file to logKey until after the MP3 file has been transcoded and uploaded to S3.
This means that we can check for the existence of the log file using AWS.s3.headObject(), and then be relatively certain that the MP3 file is ready for download once the log file is there.
We can then use AWS.s3.getSignedUrl() to generate a cryptographically signed download URL for the MP3 file that can be used to download it without any additional authentication.
You can add the following code to app.js in order to implement a route which takes in logKey and mp3Key parameters and uses them to provide a signed download URL if the MP3 file is ready.
router.get('/signed-url/:logKey/:mp3Key', (req, res) => {
const logKey = decodeURIComponent(req.params.logKey);
const mp3Key = decodeURIComponent(req.params.mp3Key);
s3.headObject({
Bucket: s3Bucket,
Key: logKey,
}, (error) => {
if (error && error.code === 'NotFound') {
res.status(200).send(JSON.stringify({ url: null }));
} else {
s3.getSignedUrl('getObject', {
Bucket: s3Bucket,
Expires: 3600,
Key: mp3Key,
}, (error, url) => {
res.status(200).send(JSON.stringify({ url }));
});
}
});
});
You can easily imagine how the response from the transcoding route could then be used to poll this signed URL route until the download is ready. That’s exactly what our bookmarklet page will do in order to trigger the download after transcoding has completed.
The Download Page Route
Finally, we get to the route that will serve as the main entry point for the YouTube MP3 downloader.
The route will just catch any URLs that don’t match either of the two previous routes, extract the video parameters from the URL, and then return a rendered HTML Nunjucks template.
The goal is that we’ll be able to just navigate to /https://www.youtube.com/watch?v=DcxxPtWAm7c or /DcxxPtWAm7c from our bookmarklet, and have that page handle kicking everything off.
router.get('/*', (req, res) => {
// Handle extracting the path from the original URL.
const originalUrl = module.parent ? req.originalUrl.slice(1) :
req.originalUrl.slice(`/${apiStage}/`.length);
const path = decodeURIComponent(originalUrl);
// Handle full youtube URLs or just the video ID.
const urlPrefixes = ['https://', 'http://', 'www.youtube.com', 'youtube.com'];
let videoId, videoUrl;
if (urlPrefixes.some(prefix => path.startsWith(prefix))) {
videoUrl = path;
videoId = videoUrl.match(/v=([^&]*)/)[1];
} else {
videoId = path;
videoUrl = `https://www.youtube.com/watch?v=${videoId}`;
}
// Render the download page template.
res.render('download.html', { apiStage, videoId, videoUrl });
});
The one tricky thing here is the check for module.parent and how it relates to extracting the URL parameters from req.originalUrl.
When we eventually deploy this API using AWS API Gateway we’re going to need to specify a “stage” for the API and this will be used as a prefix directory for the API.
We have to be a little careful with how we construct URLs in order for them to work when running the app both locally and behind API Gateway.
We’ll discuss this more later on, but, for now, just know that module.parent being non-null essentially means that we’re running on Lambda, and that originalUrl is being set to the actual string that matches the * in both cases.
In order for this route to be useful, we’ll also need to populate the download.html file.
This page will handle interacting with the rest of the API, and display an embedded YouTube video and a progress bar during transcoding.
It’s nothing too fancy, but it gets the job done.
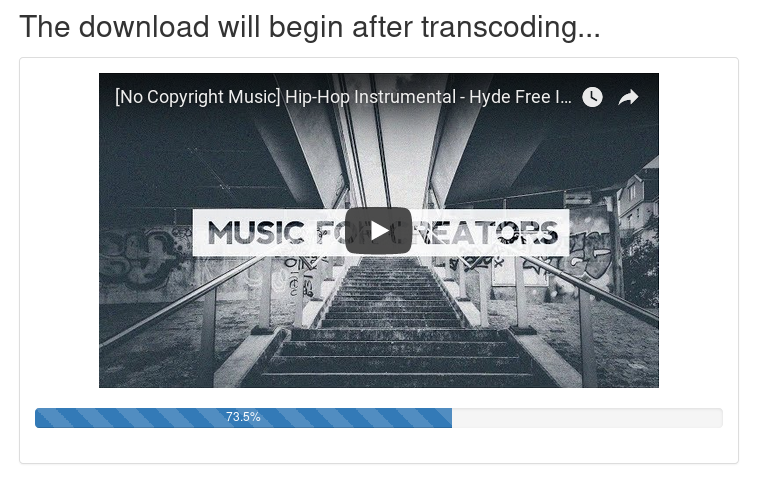
For simplicity, we’ll include the CSS and JavaScript inside of the HTML template.
The template will be rendered using Nunjucks, and three context variables will be available: apiStage, videoId, and videoUrl.
We’ll only be using basic variable substitution, so the only syntax that you need to know is that {{ variableName }} will be replaced with the value of the variableName variable.
This will allow us to set the video ID for the embdedded YouTube video, as well as to construct URLs and parameters for the API interactions.
You can make the template available to the res.render() function by placing the following content into a file called download.html in your project directory.
<!DOCTYPE html>
<html lang="en">
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type">
<meta content="utf-8" http-equiv="encoding">
<title>Youtube MP3 Downloader</title>
<link rel="stylesheet"
href="//maxcdn.bootstrapcdn.com/bootstrap/3.3.7/css/bootstrap.min.css">
<style>
.embedded-video {
display: block;
height: 315px;
margin: 0 auto 20px auto;
width: 560px;
}
</style>
</head>
<body>
<div class="container">
<h2 id="header">The download will begin after transcoding...</h2>
<div class="panel panel-default">
<div class="panel-body">
<iframe
allow="autoplay; encrypted-media"
allowfullscreen
class="embedded-video" src="https://www.youtube.com/embed/{{ videoId }}"
frameborder="0"
>
</iframe>
<div class="progress progress-striped">
<div id="progress-bar" class="progress-bar" style="width: 0%; opacity: 1;">
0%
</div>
</div>
</div>
</div>
</div>
<script type="text/javascript">
//
// Fill in the content here from the script below!!!
//
</script>
</body>
</html>
The HTML and CSS here should be mostly self-explanatory; we’re using a CDN-hosted copy of Bootstrap 3 for the styling and displaying a very basic interface. Most of the magic here is really taking place in the JavaScript tag at the end of the body. I separated it out here–so that the syntax highlighting works better–but you should include the following contents within this script tag if you’re following along with the tutorial.
// Construct the API URLs from the current window location.
const currentLocation = window.location.toString();
const apiStagePrefix = '/{{ apiStage }}/';
const apiPrefix = currentLocation.slice(0,
currentLocation.indexOf(apiStagePrefix) + apiStagePrefix.length);
const apiTranscodeUrl = `${apiPrefix}transcode/{{ videoId }}`;
const apiSignedUrl = `${apiPrefix}signed-url`;
// Handle updating the progress bar.
const progressBar = document.getElementById('progress-bar');
const updateProgress = (progress) => {
if (progress >= 1) {
progressBar.innerHTML = 'Done!';
progressBar.innerHTML = `100%`;
progressBar.parentElement.classList.remove('progress-striped');
progressBar.style= `width: 100%; opacity: 1;`;
} else {
progressBar.innerHTML = `${Math.round(progress * 1000) / 10}%`;
progressBar.style= `width: ${progress * 100}%; opacity: 1;`;
}
};
// Check the current status of the transcoding and update the progress.
const startPolling = ({ logKey, mp3Key }) => {
const url = `${apiSignedUrl}/${encodeURIComponent(logKey)}/` +
encodeURIComponent(mp3Key);
const header = document.getElementById('header');
const initialTime = Date.now();
const pollingInterval = 5000;
const poll = () => {
fetch(url)
.then(response => response.json())
.then(({ url }) => {
if (!url) {
const progress = Math.min(1, (Date.now() - initialTime) / 300000);
if (progress === 1) {
header.innerHTML = 'Something went wrong :-(';
} else {
updateProgress(progress);
setTimeout(poll, pollingInterval);
}
} else {
updateProgress(1);
header.innerHTML = 'Transcoding has completed successfully!';
window.location = url;
}
});
};
poll();
};
// Kick off the actual transcoding.
fetch(apiTranscodeUrl)
.then(response => response.json())
.then(startPolling);
The first thing that the script does is to construct URLs for the transcoding and signed URL endpoints.
It does this under the assumption that the API is hosted on /{{ apiStage }}/ at the root of the domain.
This will automatically be the case for the API Gateway deployment, and we’ll make sure in the next section that it’s also true when running the server locally.
After that, an updateProgress() function is defined for changing the position of the progress bar.
This method takes in the current progress as a fraction between zero and one, then uses this to update the styling and content of the progress bar.
It’s pretty basic, but it gives some nice visual feedback while transcoding is taking place.
Once we have that bookkeeping in place, we can move on to the actual API interactions.
We first define a startPolling() method which will hit the signed URL API endpoint once every five seconds, update the progress bar, and eventually trigger the download once a signed URL is available.
The “progress” here is a bit of a facade; we don’t actually get any measure of progress from our signed URL endpoint, so we instead just display how much of the maximum Lambda execution window has transpired.
If more than five minutes has passed, then we know that the transcoding has failed and we display an error message.
This will be the case for any really long videos that can’t be handled within a single Lambda invocation.
Finally, we kick off the actual transcoding by hitting our transcoding API route.
This route invokes our transcoding Lambda function, and returns a JSON response containing logKey and mp3Key.
We pass these response variables directly into startPolling() where they’re used to construct the full signed URL API route with the parameters included.
Running the App Locally
With all of the endpoints in place, now we just need to be able to run our app.
To accomplish this, you can add the following code to the end of your app.js file.
// Run the app when the file is being run as a script.
if (!module.parent) {
app.use(`/${apiStage}/`, router);
app.listen(3000, () => console.log('Listening on port 3000!'))
} else {
app.use('/', router);
}
// Export the app for use with lambda.
module.exports = app;
You can see that we’re again checking for module.parent here, and then handling how we connect the router to the app in different ways depending on whether or not it’s defined.
When module.parent is not defined, it means that the file is being run directly as a script with a command like node app.js.
This indicates that we’re running the server locally during development, so we need to manually add the /v1/ prefix before our API and start the server.
When module.parent is defined, it means that this module has been imported somewhere else.
This will be the case when we run on Lambda with API Gateway, so we’ll skip starting the server and leave off the API prefix in anticipation of it being added later by API Gateway.
With this last bit of code in place, you should be able to run the app with the following command.
node app.js
After that, visiting a URL like http://localhost:3000/v1/https://www.youtube.com/watch?v=DcxxPtWAm7c should render the downloader page, invoke the transcoding function, and finally start the MP3 download once it’s ready.
We had to jump through a few hoops to make our app emulate the /${apiStage}/ API Gateway prefixing, but the final result allows us to make sure that everything can be run locally without needing to emulate the Lambda environment.
Lambdifying the Express App
In order to run our app on AWS Lambda, we’ll need to expose a handler function that takes in event and context objects.
Our Express app is designed to accept HTTP requests, and it will require a bit of extra glue to allow it to work with API Gateway invocations of our Lambda function.
This would be a bit of a pain to do by hand, but there’s a library called aws-serverless-express which makes it really easy.
You can install it in your project directory by running
yarn add aws-serverless-express
and then add the following content to a file called lambda.js.
const awsServerlessExpress = require('aws-serverless-express');
const app = require('./app');
const server = awsServerlessExpress.createServer(app);
exports.handler = (event, context) => (
awsServerlessExpress.proxy(server, event, context)
);
This code imports our Express app from app.js, creates a server for the app, and then exports a Lambda handler function which proxies API Gateway events to the app’s server.
We’ll just need to specify lambda.handler as our handler when we create the corresponding Lambda function, and the same app that runs locally should work out of the box with API Gateway.
Deploying the App on AWS
In the previous installment of this tutorial, we set up a AWS Identity and Access Management (IAM) role with the necessary access policies for running the YouTube MP3 app that we developed in the previous section.
We’ll be using that role now, so you’ll need to set a role_arn environment variable in your terminal to the correct role ARN.
For me, that’s
export role_arn="arn:aws:iam::421311779261:role/YoutubeMp3DownloaderRole"
but this will be something different for you. You can run the aws iam list-roles command to see all of your available IAM roles if you aren’t sure which ARN to use here.
Creating the Lambda Function
We already designed our app in such a way that it could run on Lambda and integrate with AWS Gateway, so now we just need to package up and deploy that existing code. The first step here is to create a ZIP file that includes all of our code and the dependencies it needs to run. This can be done by running the following command.
zip --symlinks --recurse-paths youtube-mp3-downloader.zip \
app.js lambda.js package.json node_modules/
When we deployed our transcoder function earlier, we uploaded our ZIP file to S3 as a work-around for the AWS command-line tools being a bit flaky about uploading large code bundles.
This ZIP file is quite a bit smaller, only 8.5 MB, so we can skip that extra step and just upload the file directly.
The path to the code bundle can be specified using the --zip-file argument when we use aws lambda create-function to actually create our Lambda function.
# Store the function name for later.
export downloader_function_name="YoutubeMp3DownloaderFunction"
# Create the function for the downloader app's API.
response="$(aws lambda create-function \
--function-name "${downloader_function_name}" \
--zip-file fileb://youtube-mp3-downloader.zip \
--handler lambda.handler \
--runtime nodejs6.10 \
--timeout 29 \
--role "${role_arn}")"
# Echo the response in the terminal.
echo "${response}"
# Store the function ARN for future usage.
downloader_function_arn="$(jq -r .FunctionArn <<< "${response}")"
You can see that we’re following the same general pattern that we used in the first tutorial: first storing the initial response in an environment variable, then using jq to extract and store values from JSON responses. We’ll need to know the function ARN when we set up the API Gateway integration later on, and this pattern makes it easy to copy and paste code without needing to change command-line arguments manually. The full JSON response will also be echoed to the terminal, and it should look something like this.
{
"FunctionName": "YoutubeMp3DownloaderFunction",
"FunctionArn": "arn:aws:lambda:us-east-2:421311779261:function:YoutubeMp3DownloaderFunction",
"Runtime": "nodejs6.10",
"Role": "arn:aws:iam::421311779261:role/YoutubeMp3DownloaderRole",
"Handler": "lambda.handler",
"CodeSize": 8845340,
"Description": "",
"Timeout": 29,
"MemorySize": 128,
"LastModified": "2018-04-07T18:53:45.370+0000",
"CodeSha256": "2U9hJ+J04aNQbBjlSse38KLYCwZDMh+aJDjxntFoN2o=",
"Version": "$LATEST",
"TracingConfig": {
"Mode": "PassThrough"
},
"RevisionId": "70df98f5-107e-480d-9f5c-1718742d42f1"
}
If you need to make any code changes and deploy them, you can make a new ZIP file and use aws lambda update-function-code to upload the new version.
zip --symlinks --recurse-paths youtube-mp3-downloader.zip \
app.js lambda.js download.html package.json node_modules/
aws lambda update-function-code \
--zip-file fileb://youtube-mp3-downloader.zip \
--function-name "${downloader_function_name}"
We should now be able to directly invoke our Lambda function as long as all of the commands so far have succeeded.
The one thing that we need to figure out first is how we can invoke it with a meaningful Lambda event that will result in one of our Express app’s routes being used.
The fact that we’re using aws-serverless-express means that our lambda.handler function expects the same event object format that API Gateway will send during invocations.
There’s an example api-apigateway-event.json file included in the aws-serverless-express repository, and we can use that as a basis to construct a test event ourselves.
read -r -d '' downloader_event <<'EOF'
{
"resource": "/{proxy+}",
"path": "/DcxxPtWAm7c",
"httpMethod": "GET",
"headers": null,
"queryStringParameters": null,
"pathParameters": {
"proxy": "DcxxPtWAm7c"
},
"stageVariables": null,
"requestContext": {
"path": "/{proxy+}",
"accountId": "421311779261",
"resourceId": "sqlu6a",
"stage": "test-invoke-stage",
"requestId": "test-invoke-request",
"identity": {
"cognitoIdentityPoolId": null,
"cognitoIdentityId": null,
"apiKey": "test-invoke-api-key",
"cognitoAuthenticationType": null,
"userArn": "arn:aws:iam::421311779261:root",
"apiKeyId": "test-invoke-api-key-id",
"userAgent": "aws-internal/3",
"accountId": "421311779261",
"caller": "421311779261",
"sourceIp": "test-invoke-source-ip",
"accessKey": "ASIAJX5RHRK4I43HZAQA",
"cognitoAuthenticationProvider": null,
"user": "421311779261"
},
"resourcePath": "/{proxy+}",
"httpMethod": "GET",
"extendedRequestId": "test-invoke-extendedRequestId",
"apiId": "osacfvxuq7"
},
"body": null,
"isBase64Encoded": false
}
EOF
One important thing to notice here is that the original request path for the API Gateway request is stored in path.
The request path in this event corresponds to /DcxxPtWAm7c–the video ID for this hip hop instrumental video.
Another important point is that all of the extracted path parameters are stored in pathParameters.
We can see here that the entire request path has been stored in a parameter called proxy.
It’s possible to do complex routing in API Gateway, but aws-serverless-express expects to find the full path in this proxy parameter so that it can pass it on to the Express app’s router.
In this case, our constructed event translates into a request that’s roughly equivalent to the following.
curl http://localhost:3000/v1/DcxxPtWAm7c
We can now use the aws lambda invoke command to actually invoke our downloader Lambda function using the test event stored in the downloader_event environment variable.
# Invoke our transcoder function with this test event.
aws lambda invoke \
--function-name "${downloader_function_name}" \
--payload "${downloader_event}" \
/dev/stdout
The event will get translated into something that our express app can understand, and eventually handled by the endpoint which renders the download.html template.
The /dev/stdout argument in the above command specifies where the function response should be written out to, so something similar to the following should be printed to the terminal when you run the command.
{
"statusCode":200,
"body": "// Rendered HTML has been removed for brevity.",
"headers":{
"x-powered-by":"Express",
"content-type":"text/html; charset=utf-8",
"content-length":"3395",
"etag":"W/\"d43-pDm03tYFXd4TxnLz6ZV0YE/MyTQ\"",
"date":"Sat, 07 Apr 2018 19:40:38 GMT",
"connection":"close"
},
"isBase64Encoded":false
}
I’ve removed the actual HTML content from the response because it’s really long, but you can get the general idea from this.
Just like how aws-serverless-express translates request events from API Gateway into a format that our Express app can understand, it also translates our app’s responses into a format that API Gateway can understand.
The value of statusCode will determine the responses status code, the value of body will populate the response’s body, headers defines the response headers, etc.
Creating the API Gateway Integration
Now it’s just a matter of creating an API Gateway resource which integrates with Lambda and produces events in the format that aws-serverless-express expects.
First, we’ll need to create a new API using the aws apigateway create-rest-api command.
# Set the name for the API.
export downloader_api_name="YoutubeDownloaderApi"
# Create a new REST API.
response="$(aws apigateway create-rest-api \
--name "${downloader_api_name}" \
--endpoint-configuration types=REGIONAL)"
# Echo the response in the terminal.
echo "${response}"
# Store the API ID for future usage.
api_id="$(jq -r .id <<< "${response}")"
This should echo at a response similar to the following, the most important part of which is the API’s ID that we store in the api_id environment variable.
{
"id": "osacfvxuq7",
"name": "YoutubeDownloaderApi",
"createdDate": 1523128092,
"apiKeySource": "HEADER",
"endpointConfiguration": {
"types": [
"REGIONAL"
]
}
}
Creating the API will also automatically create a root resource at / that we’ll need to specify as the parent of any additional resources that we create.
We can query the API’s resources using aws apigateway get-resources and then store the resource ID in the root_resource_id environment variable.
# Query the resources for this API.
response="$(aws apigateway get-resources \
--rest-api-id "${api_id}")"
# Echo the response in the terminal.
echo "${response}"
# Store the root resource ID for future usage.
root_resource_id="$(jq -r .items[0].id <<< "${response}")"
Running this command should output a list of resource items which, at this time, consists of only the root resource with a path of /.
{
"items": [
{
"id": "i287fb3kv1",
"path": "/"
}
]
}
Now we’ll need to create a child resource using aws apigateway create-resource.
This API resource will be the one that integrates with our downloader Lambda function.
The most important thing to note here is that we’re specifying {proxy+} as the path segment for this resource.
The parameter name here is proxy, just because that’s what aws-serverless-express expects it to be, and the + signifies that this is a greedy path variable.
Basically, this resource will match any requests to our API, store the full path in proxy, and then pass on the event to our Lambda function where the full path will be matched against our own Express router.
# Create a child proxy resource.
response="$(aws apigateway create-resource \
--rest-api-id "${api_id}" \
--parent-id "${root_resource_id}" \
--path-part '{proxy+}')"
# Echo the response in the terminal.
echo "${response}"
# Store the proxy resource ID for future usage.
proxy_resource_id="$(jq -r .id <<< "${response}")"
Running this command will echo out a few details of the newly created resource if everything worked successfully.
{
"id": "sqlu6a",
"parentId": "i287fb3kv1",
"pathPart": "{proxy+}",
"path": "/{proxy+}"
}
Now we’ll need to explicitly allow GET requests for this method using aws apigateway put-method.
# Allow GET requests for the proxy resource.
aws apigateway put-method \
--rest-api-id "${api_id}" \
--resource-id "${proxy_resource_id}" \
--http-method GET \
--authorization-type NONE
If our API had also accepted other request types, we would need to explicitly add these methods here as well.
This is also the place where you would set an authorization type if you didn’t want to just leave the API completely open to the public.
We’ve opted to keep things simple here, and the put-method command should echo out the details of the request method that we added without any authorization handler.
{
"httpMethod": "GET",
"authorizationType": "NONE",
"apiKeyRequired": false
}
Next, we’ll need to integrate our proxy resource with the downloader Lambda function. This can be done by providing the various resource identifiers for the integration to aws apigateway put-integration.
# Integrate the proxy resource with the downloader Lambda function.
aws apigateway put-integration \
--rest-api-id "${api_id}" \
--resource-id "${proxy_resource_id}" \
--http-method GET \
--integration-http-method POST \
--type AWS_PROXY \
--uri "arn:aws:apigateway:us-east-2:lambda:path/2015-03-31/functions/${downloader_function_arn}/invocations" \
--credentials "${role_arn}"
We won’t need to store anything from the output of the command, but you can expect the response to look something like this.
{
"type": "AWS_PROXY",
"httpMethod": "POST",
"uri": "arn:aws:apigateway:us-east-2:lambda:path/2015-03-31/functions/arn:aws:lambda:us-east-2:421311779261:function:YoutubeMp3DownloaderFunction/invocations",
"credentials": "arn:aws:iam::421311779261:role/YoutubeMp3DownloaderRole",
"passthroughBehavior": "WHEN_NO_MATCH",
"timeoutInMillis": 29000,
"cacheNamespace": "sqlu6a",
"cacheKeyParameters": []
}
This brings us to our very last step: we need to actually create the deployment for our API using aws apigateway create-deployment.
Note that we’re specifying the stage name as v1 here, the same value that we used to prefix the URL routes when running our app locally.
The value of the API stage doesn’t really matter, we just wanted it to be consistent for the purposes of constructing URLs.
# Deploy the API with a stage name of "v1".
aws apigateway create-deployment \
--rest-api-id "${api_id}" \
--stage-name v1
This final command will then echo back the deployment resource ID and creation date.
{
"id": "6hzvwr",
"createdDate": 1523129518
}
At this point, our API should be live. The general pattern for where Amazon hosts APIs is this.
https://{restapi-id}.execute-api.{region}.amazonaws.com/{stage}/
Substituting in the values with the ones that we’ve been using gives us the base URI for our API. For me, this looks something like this
https://osacfvxuq7.execute-api.us-east-2.amazonaws.com/v1/
but you’ll need to substitute in your values because we won’t be making this service publicly available like we did with the CircleCI Artifacts API. Appending either a YouTube video ID or URL to the end of this will load the download page that we developed earlier, just like when we were running the app locally.
The Bookmarklet
All of the hard work is behind us now, we just need an easy way to navigate to the API’s download page when we want to download an MP3. We constructed our API in such a way that all we need to do is append a YouTube video URL to the end of our API in order to load the download page for that video. This means that we can just execute the following line of JavaScript on any YouTube video page, and it will open the video’s download page in a new tab.
window.open(`https://osacfvxuq7.execute-api.us-east-2.amazonaws.com/v1/${window.location.href});
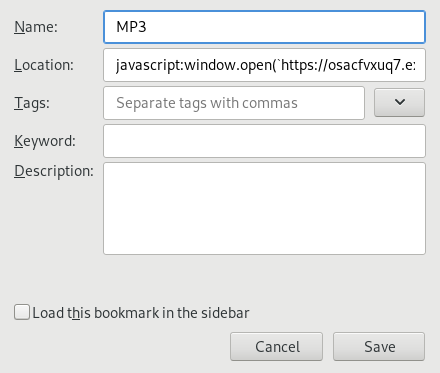
In order to turn this into a bookmarklet, we simply need to prefix it with javascript: and then add it as a bookmark.
javascript:window.open(`https://osacfvxuq7.execute-api.us-east-2.amazonaws.com/v1/${window.location.href}`);
Most modern browsers support bookmarklets formatted in this way, and will execute the JavaScript code in the current page whenever you click on the bookmark. Here’s an example of how you would configure the bookmark location in Firefox.
After adding the bookmarklet, you simply need to click on it from any YouTube video page in order to open the download page we built and kick off the transcoding process. I know you’ve seen this video once already, but let’s take a look at the whole process again now that we’ve seen how all of the pieces fit together.
Conclusion
Thanks for taking the time to read our two part guide on building a YouTube MP3 Downloader using AWS Lambda. Regardless of whether you’re actually interested in transcoding YouTube videos, many of the techniques that we covered here can be quite effective when working with Lambda in general. Using Exodus to bundle complex native binaries with their dependencies, prototyping APIs with Express and then adapting them to Lambda with aws-serverless-express, and storing Lambda function output files on S3 using the aws-sdk are all common and useful patterns. We hope that you found it useful to see practical examples of employing these techniques!
If you’re interested in checking out more great content from Intoli, then feel free to browse through other articles on our blog or to subscribe to our monthly article newsletter. You can also star or follow our intoli-article-materials repository on GitHub to find out about new articles, often even before they are published!
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.

Performing Efficient Broad Crawls with the AOPIC Algorithm
Learn how to estimate page importance and allocate bandwidth during a broad crawl.
Breaking Out of the Chrome/WebExtension Sandbox
A short guide to breaking out of the WebExtension content script sandbox.

User-Agents — Generating random user agents using Google Analytics and CircleCI
A free dataset and JavaScript library for generating random user agents that are always current.
Comments