By Evan Sangaline | September 7, 2017
There’s a First Time for Everything
Like some 75 million other Americans, I am playing fantasy football this year. Unlike most of them, I know virtually nothing about football. I would estimate that I’ve watched somewhere around five games total in my life, most of them Super Bowls. I don’t know the rules beyond the very basics and I can’t name a single NFL player off the top of my head.
This lack of knowledge is no doubt a significant handicap, but I’m hoping that I can make up for it in other areas. I’m equally as strong in areas like statistics, programming, machine learning, and simulation as I am weak in knowledge of football. Within my league, I am quite probably the best and the worst on these two respective fronts.
There are plenty of people out there who are strong in both categories, but I find it somewhat interesting to be positioned at two opposite extremes. In particular, I think that this puts me in a good position to describe basic components of strategy to people who have backgrounds similar to my own (e.g. hackers who know nothing about football). I’ll make minimal assumptions about acronyms and rules of the game, but I’ll use analytical methods which–although far from state of the art–are technically interesting in their own right.
I’ll start off with this introductory article on how I’m constructing my draft strategy. The draft basically consists of teams taking turns picking their next player, and making smart decisions about each pick is essential for ending up with a strong team. My plan is to write Python code to scrape projections and use them to construct an algorithm that helps me make those smart decisions. If we get feedback that this sort of article is filling a useful niche, then perhaps I’ll also write about trading strategies and more detailed simulations in the future!
Understanding the Very Basics
The basic idea behind Fantasy Football is that you make a virtual team of real players and then your team earns some total number of points based on the performance of its players in their respective real-world games. Your team is matched up against a different virtual team in your league each week and whichever team gets more points wins. One obvious way to award points would be to just get the same number of points that each player on your team scores in each of their games. Admittedly, that’s how I had vaguely imagined that things worked up until fairly recently, but there are a couple of reasons why it wouldn’t make a good system.
If you were to just award each virtual team with the same points that their players get, then there would be some positions that are very valuable and others that are basically worthless. A player who is the best in the NFL in a defensive position might be worth less than a relatively mediocre player with a solely offensive position. The other big issue with this approach is that there is a lot of randomness in how many touchdowns a player scores in a game. Most players probably score no points during a game and this isn’t necessarily the result of them not playing well.
To address these problems, a more complicated scoring system is used. Different point amounts are assigned to different actions such that all of the positions are valuable and the impact of randomness is significantly reduced. For example, a player might lose points for fumbling the ball or gain some number of points for every yard that they run. Here is some Python code that expresses the specific rules for my league and how the points are calculated from those rules.
player_rules = {
'pass yds': 0.04, # Pass Yards
'pass tds': 4, # Pass Touchdowns
'int': -2, # Interceptions
'rush yds': 0.1, # Rush Yards
'rush tds': 6, # Rush Touchdowns
'rec yds': 0.1, # Reception Yards
'rec tds': 6, # Reception Touchdowns
'fum': -2, # Fumbles
'10-19 fgm': 3, # 10-19 Yard Field Goal
'20-29 fgm': 3, # 20-29 Yard Field Goal
'30-39 fgm': 3, # 30-39 Yard Field Goal
'40-49 fgm': 3, # 40-49 Yard Field Goal
'50+ fgm': 5, # 50+ Yard Field Goal
'xpm': 1, # Extra Point
}
def calculate_player_points(performance):
points = 0
for rule, value in player_rules.items():
points += float(performance.get(rule, 0))*value
return points
The performance parameter here is a dictionary containing how many of each action a player performed in a game.
I’m not really a big fan of using these abbreviations as the keys, but it will make sense why I chose these once we start looking at external data sources.
In addition to the individual player performance, there’s a special “Defence” position which corresponds to an entire real team’s defensive performance. If anybody on the team makes an interception or makes a defensive touchdown, then it gets attributed to the team. The analogous rules and points calculation looks like this.
team_rules = {
'scks': 1, # Sacks
'int': 2, # Interceptions
'fum': 2, # Fumbles
'deftd': 6, # Defensive Touchdowns
'safts': 2, # Safeties
}
def calculate_team_points(performance):
points = 0
for rule, value in team_rules.items():
points += float(performance[rule])*value
# special brackets for "Points Against"
points_against = float(performance['pts agn'])
if points_against == 0:
points += 10
elif points_against < 7:
points += 7
elif points_against < 14:
points += 2
return points
If we specify the position in performance['position'] and let D denote defence, then we can make a more general calculate_points() method which can handle the defensive team position as well as the regular player positions.
def calculate_points(performance):
if performance['position'] == 'D':
return calculate_team_points(performance)
return calculate_player_points(performance)
There are some more fundamental concepts that we’ll need to go over, but let’s first take a look at getting some data on the different players that we can use to calculate points. We’ll revisit some of the rules surrounding teams and lineups once we’ve explored individual player values and developed a little more intuition for the different positions.
Scraping Projections
If we have predictions for what each player’s performance for the different actions will be like in each game, then we can predict what their total number of points will be using the calculate_points() function that we defined earlier.
Doing this from scratch would be a large undertaking, but luckily there are a number of websites out there which provide the exact predictions that we need.
The one that I’ll use here is Fantasy Sharks, a free site that provides fairly detailed weekly projections.
Here is an example of what the projections look like on the Fantasy Sharks website.

You can see now why I chose the abbreviated dictionary keys earlier; they match up exactly with the table headers on the Fantasy Sharks projections. That will make it easier to use these projections to calculate the number of points that each player is expected to play. You might also notice that there’s a tooltip visible in the screenshot saying that Andrew Luck is uncertain for Week 1. I included this to emphasize that there is more to strategy than point projections because things like injuries and suspensions can cause actual points to differ wildly from projections. I’ll take a very projection-centric approach, but this is more because of my limited understanding of these other components of the game than anything else.
To scrape the Fantasy Sharks projections, we’ll start with a simple fetch_projections_page() method that constructs the URL and fetches the projections for a specific position and week in the season.
import urllib.request
def fetch_projections_page(week, position_id):
assert 1 <= week <= 17, f'Invalid week: {week}'
base_url = 'https://www.fantasysharks.com/apps/bert/forecasts/projections.php'
url = f'{base_url}?League=-1&Position={position_id}&scoring=1&Segment={595 + week}&uid=4'
request = urllib.request.Request(url)
request.add_header('User-Agent', 'projection-scraper 0.1')
with urllib.request.urlopen(request) as response:
return response.read()
Then to construct the full projections, we simply need to loop through the 16 weeks in the season and the six positions that we’re interested in.
The position abbreviations and ids here in the position_map here were just figured out by visiting the various projection pages manually.
import time
from bs4 import BeautifulSoup
def scrape_projections():
for week in range(1, 17):
position_map = { 'RB': 2, 'WR': 4, 'TE': 5, 'QB': 1, 'D': 6, 'K': 7 }
for position, position_id in position_map.items():
time.sleep(5) # be polite
html = fetch_projections_page(week, position_map[position])
soup = BeautifulSoup(html, 'lxml')
table = soup.find('table', id='toolData')
header_row = table.find('tr')
column_names = [th.text for th in header_row.find_all('th')]
for row in table.find_all('tr'):
column_entries = [tr.text for tr in row.find_all('td')]
# exclude repeated header rows and the "Tier N" rows
if len(column_entries) != len(column_names):
continue
# extract Fantasy Shark's player id
player_link = row.find('a')
player_id = int(player_link['href'].split('=')[-1].strip())
# yield a dictionary of this player's weekly projection
player = { 'id': player_id, 'week': week, 'position': position }
for key, entry in zip(column_names, column_entries):
player[key.lower()] = entry
yield player
Running this will generate a sequence of projections which correspond to the expected performance of a player in a given week.
We can pass any one of these weekly projections to our calculate_points() method and get the expected number of points given the specific rules in my league.
You might have noticed that there was actually a PTS column on the Fantasy Sharks website which is supposed to correspond to the total projected points.
Those points are calculated using a different set of rules than our custom league rules and therefore the projected points are different.
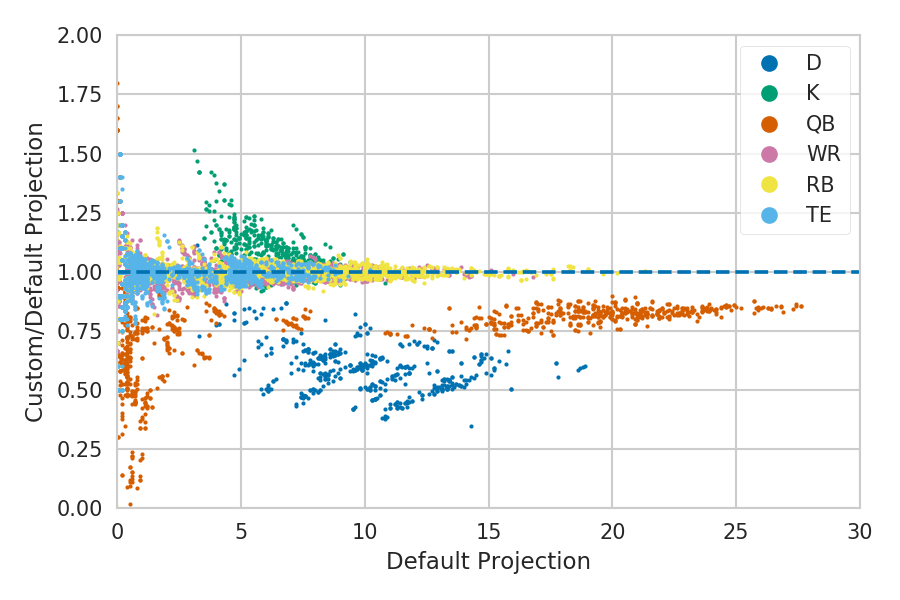
Looking at the ratio of projected points given our custom league rules to those given the default rules, you can see that the Wide Receivers (WR) and Quarter Backs (QB) both systematically receive less points in our league than they would with default scoring. Using the default score projections would have therefore resulted in me over-valuing those positions. There are also a number of tools out there that let you enter in your own rules though, so this isn’t really a unique advantage or anything.
Basic Weekly Point Projections
One interesting thing to look at is how the point projections are distributed for the different positions.
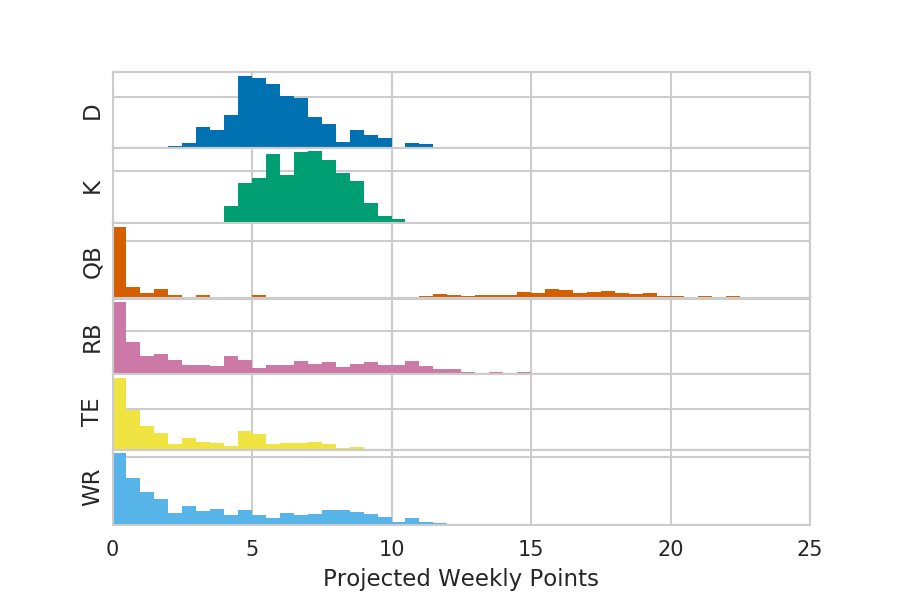
We can see here that the quarter backs are the highest scorers and that there’s really a huge gap between the higher and lower scorers. The Kickers (K) and Defence (D) are somewhat similar to each other, both getting around 5-10 points per game and much more unimodally distributed. The Running Backs (RB) and Wide Receivers (WR) seem to be roughly comparable, perhaps with the best running backs being slightly higher scorers. Finally, the Tight Ends (TE) seem to be similar to the lower scoring wide receivers and running backs.
This gives some insight into how valuable the different positions will be in the end, but scarcity and strategy matter a lot as well. The difference in points between a really good kicker and a bad kicker is much smaller than the difference between a really good running back and a bad running back. For this reason, it would be far preferable to have a good running back and a bad kicker than vice versa. Prioritizing a running back pick over a kicker might make sense then, even if the kicker is projected to score more points. The details of all this really depend on the number of teams and the specific team compositions though.
Baseline Subtracted Projections
One of the key rules of Fantasy Football that I haven’t mentioned yet is that there is a concept called waiver wires. There is a limit to the number of players that you can have on your fantasy team and the limit is low enough that there are always a number of players who aren’t on anybody’s team. You have the option at some times during the week to drop a player from your team and pick up a player off the “waiver wire” (the players that aren’t currently on a team). If the teams are somewhat equilibrated then it kind of makes more sense to think of a player’s value as how much better they are than the freely available replacement players rather than how many raw points they will score. We can essentially consider the projections of the best available replacement player for each position as a sort of baseline, subtract the appropriate baseline from the projections for each of the players, and then use these baseline subtracted projections to compare the values of players in different positions more fairly.
Of course, we’ll need to have some idea of how the teams will be composed in order to know how good the replacement players for each position will be. This requires us to get into some of the larger scale rules of the league and to estimate what the team rosters will end up looking like. We’ll implement a basic representation of how the teams function in Python code and then use this to form our estimates of the rosters and calculate player values relative to the waiver wire players.
My league uses a site called BestFantasyFootballLeague.com and our league is called a “MiniFLEX” league. There are 12 teams in our league and a limit of 18 players per team, resulting in a total of 216 players that will be on a team at any given time. Despite there being 18 players on a team, you have to pick 9 starting players to actually “play” each week. Those are the only players who can score points and in a MiniFLEX league you need to specifically play:
1 QB, 2 RB, 2 WR, 1 TE, 1 FLEX (choose from one WR, RB, or TE), 1 K, and 1 D.
We’ve seen all of these abbreviations before, except for FLEX which is defined as your choice of wide receiver, running back, or tight end.
We’ll eventually want to build up to representing an entire team in code, but first let’s build a cleaner abstraction for the individual players.
Our projections so far have all been individual weekly projections without any concept of a player’s performance across weeks.
We can build a simple Player class that aggregates the point projections across weeks
class Player:
def __init__(self, id, position, name, team):
self.id = id
self.position = position
self.name = name
self.team = team
self.points_per_week = [0]*18
def add_projection(self, projection):
assert self.id == projection['id']
self.points_per_week[projection['week']] = calculate_points(projection)
def season_points(self):
return sum(self.points_per_week)
def week_points(self, week):
assert 1 <= week <= 17
return self.points_per_week[week]
and then populate a players_by_id dictionary with the Player object for each actual player.
players_by_id = {}
for projection in scrape_projections():
player = players_by_id.get(projection['id'])
if not player:
player = Player(projection['id'], projection['position'], projection['player'], projection['tm'])
players_by_id[projection['id']] = player
player.add_projection(projection)
Note that the id here is actually the ID that Fantasy Sharks uses internally.
Now we can build an analogous Team class which is capable of computing the team’s projected points for a single week or for the entire season.
class Team:
allowed_flex_positions = ['RB', 'TE', 'WR']
maximum_players = 18
starting_positions = ['K', 'D', 'FLEX', 'QB', 'RB', 'RB', 'TE', 'WR', 'WR']
weeks = list(range(1, 17))
def __init__(self):
self.players_by_id = {}
def add_player(self, player):
assert self.player_count() < self.maximum_players
self.players_by_id[player.id] = player
def remove_player(self, player):
del self.players_by_id[player.id]
def clear_players(self):
self.players_by_id = {}
def players(self):
return self.players_by_id.values()
def player_count(self):
return len(self.players_by_id)
def team_full(self):
return self.player_count() == self.maximum_players
def starters(self, week):
remaining_players = sorted(self.players_by_id.values(),
key=lambda player: player.week_points(week), reverse=True)
starters = []
flex_count = 0
for position in self.starting_positions:
# we'll handle flex players later
if position == 'FLEX':
flex_count += 1
continue
# fnd the best player with this position
for i, player in enumerate(remaining_players):
if player.position == position:
starters.append(player)
del remaining_players[i]
break
# do the same for flex players
for i in range(flex_count):
for j, player in enumerate(remaining_players):
if player.position in self.allowed_flex_positions:
starters.append(player)
del remaining_players[j]
return starters
def season_points(self):
return sum((self.week_points(week) for week in self.weeks))
def week_points(self, week):
return sum((player.week_points(week) for player in self.starters(week)))
The logic here is a bit more complicated, but it mainly consists of picking the best starting line-up each week and then calculating the projected points for only the starters.
Finally, we can add one higher level abstraction to represent the entire league.
from collections import defaultdict
import random
class League:
number_of_teams = 12
team_class = Team
def __init__(self, players):
self.teams = [self.team_class() for i in range(self.number_of_teams)]
self.all_players = [player for player in players]
self.available_players = [player for player in players]
def clear_teams(self):
self.available_players = [player for player in self.all_players]
for team in self.teams:
team.clear_players()
def calculate_baselines(self):
projections = defaultdict(list)
for player in self.available_players:
points = sum((player.week_points(week) for week in self.teams[0].weeks))
projections[player.position].append(points)
return { position: max(points) for position, points in projections.items() }
def optimize_teams(self, same_positions=False):
# cycle through and pick up available players
optimal = False
trades = 0
while not optimal:
optimal = True
for team in sorted(self.teams, key=lambda t: random.random()):
for original_player in list(team.players()):
# find the best trade with available players
original_points = team.season_points()
team.remove_player(original_player)
best_player, best_points = original_player, original_points
for new_player in self.available_players:
if same_positions and new_player.position != original_player.position:
continue
# don't bother computing if the new player is strictly worse
if new_player.position == original_player.position:
for week in team.weeks:
if new_player.week_points(week) > original_player.week_points(week):
break
else:
# strictly worse
continue
team.add_player(new_player)
new_points = team.season_points()
if new_points > best_points:
best_points = new_points
best_player = new_player
team.remove_player(new_player)
# update the team if an available player is better
if best_player != original_player:
optimal = False
trades += 1
self.available_players.append(original_player)
self.available_players.remove(best_player)
team.add_player(best_player)
else:
team.add_player(original_player)
def fill_teams_greedily(self):
self.clear_teams()
for i in range(self.team_class.maximum_players):
for team in sorted(self.teams, key=lambda t: random.random()):
best_player, best_points = None, None
for new_player in self.available_players:
team.add_player(new_player)
new_points = team.season_points()
if not best_player or new_points > best_points:
best_points = new_points
best_player = new_player
team.remove_player(new_player)
team.add_player(best_player)
self.available_players.remove(best_player)
def randomize_teams(self):
self.clear_teams()
for team in self.teams:
while not team.team_full():
index = random.randint(0, len(self.available_players) - 1)
team.add_player(self.available_players.pop(index))
def set_weeks(self, weeks):
for team in self.teams:
team.weeks = weeks
Most of the code here relates to populating the teams with players.
The randomize_teams() method populates the teams randomly while fill_teams_greedily() attempts a sort of pseudo-draft where each team chooses the player that will increase their season projection the most at each pick.
Finally, optimize_teams() simulates the teams dropping and picking up players off the waiver wire to improve their projected scores until the teams stablize.
This is a bit crude, but the basic idea is to approach a realistic equilibrium in terms of the team compositions.
We can now use an instance of League to find the season projections for the best player of each position who is still available on the waiver wire after equilibrium is reached.
# populate the teams and bring them to equilibrium
league = League(players_by_id.values())
league.fill_teams_greedily()
league.optimize_teams()
# calculate the waiver wire baselines
baselines = league.calculate_baselines()
This gives baseline season projections as listed in the following table.
| Position | Baseline Points |
|---|---|
| D | 87.93 |
| K | 94.57 |
| QB | 246.08 |
| RB | 72.27 |
| TE | 70.31 |
| WR | 72.75 |
It’s reassuring to see that running backs, tight ends, and wide receivers all have fairly similar values.
The fact that all three can be played in the FLEX position means that a big difference between the projections would likely indicate an inefficient team composition, something that optimize_teams() explicitly tried to avoid.
It’s also interesting to note that quarter backs have such a high baseline compared to the other positions. This is largely due to the fact that there are only 12 starting quarter backs while there are at least 24 running backs and 24 wide receivers. If each team were allowed two quarter backs, then their baseline would likely plummet. We took the starting line-up rules into account when simulating the team rosters and the league’s relative scarcity for the different positions is therefore reflected in these baselines.
Now we can subtract off these baselines from each player’s season projection and see how the players in each position compare.
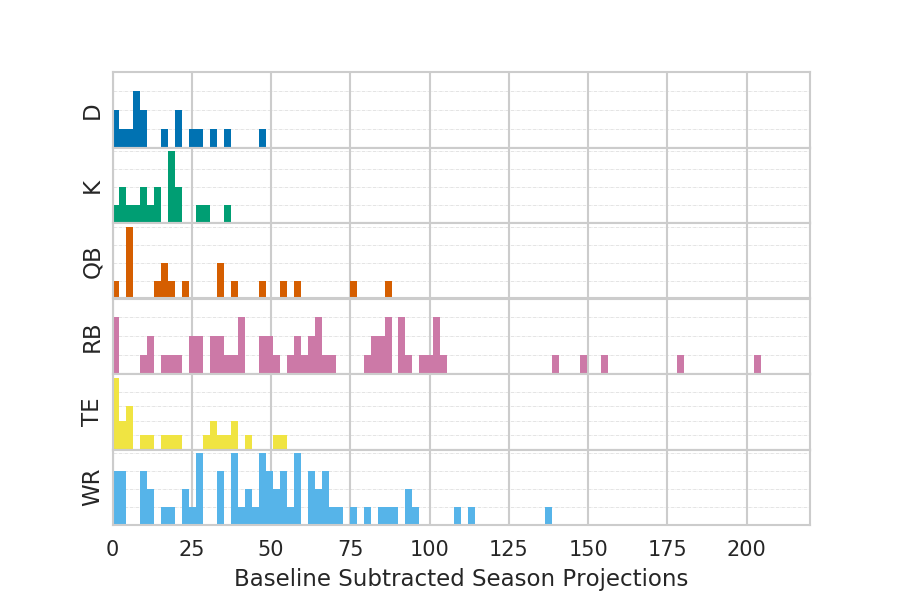
It seems that the most valuable players are running backs followed closely by wide receivers, and I would suspect these positions to dominate the first few draft rounds. It’s also interesting how much more valuable the top six players are than everybody else. I have the 12th pick in my league and counting down from the most valuable player, David Johnson with a value of 204.6, to the 12th most valuable player, Lamar Miller of 96.9, there is a tremendous drop in value.
My Draft Algorithm
The drafting site that we used allowed you to rank all of the players ahead of time and it would automatically pick the next best available player if you didn’t make a choice quickly enough. I filled this out using the baseline subtracted season projections before the draft and ended up relying on it very heavily in the later rounds. I tried to get a bit fancy in the earlier rounds by putting together a little tool to help me make my picks.
The tool calculates the season projection of points for my team and then sorts the available players based on how much they would improve my team’s total projected points if they were my next pick. Instead of using the baseline subtracted projections for the players, I calculated my weekly projected points for each position as the greater value between those of the player on my team that I could play and those of a hypothetical baseline player that I could pick up from the waiver wire. This had the same basic effect as doing the baseline subtraction, but it felt more intuitive and accurate to me in terms of considering the team composition on a weekly basis.
I also added a concept of “Throwaway Games” where I could specify some number of games which would be ignored when calculating the improvements to my team’s projected points. I set this to two initially and this allowed my time to coalesce strongly around 14 of the 16 total games. If you look at a screenshot of the tool, you can see that my first six picks all shared the same two byeweeks (those are the weeks where they don’t play in real life and therefore can’t score points).
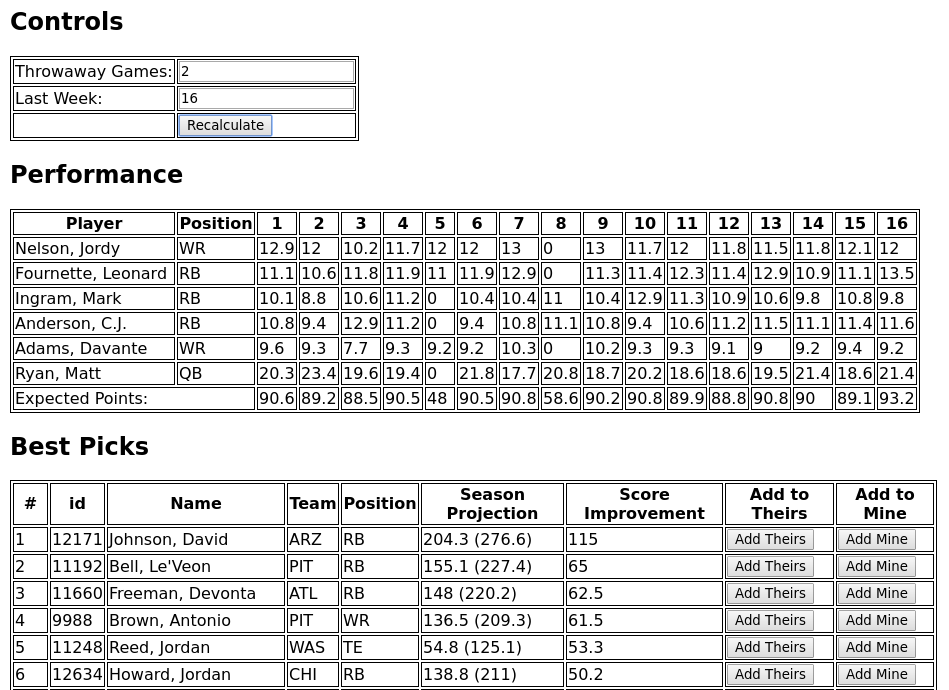
I turned the “Throwaway Games” parameter down to zero after my initial roster filled to improve my coverage of weeks 5 and 8, but it was clear that this algorithm didn’t do as well for the later draft picks. In retrospect, I would have liked to add a parameter to control calculating the season projections averaged over different scenarios of my current player’s being injured. This would have allowed me to put together a team that was more robust against injuries, something that I realized was really lacking once my initial roster was filled. I’ll likely try to incorporate something like this into my future trade algorithms.
Conclusions

Well, that’s the story of how I stumbled through my first Fantasy Football draft with very little knowledge of, or experience with, football. I have no illusions that any of this was anywhere close to an optimal strategy, but I wanted to figure things out for myself and think I did reasonably well all things considered. I’m pretty sure that I didn’t embarrass myself too badly and a couple people even included me in their playoff predictions! In any case, I certainly had a lot of fun with it and I would like to say a big thanks to everyone in my league, especially to Ted for giving me advice and to Max for hosting us.
I really hope that some people were able to find this interesting. Please feel free to reach out and let me know if you would be interested in future articles about more advanced strategies during the season. We’re also available to hire for consulting and contracting services relating to data acquisition and analysis. If that’s something that you’re looking for help with then please do get in touch!.
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.

Recreating Python's Slice Syntax in JavaScript Using ES6 Proxies
A gentle introduction to JavaScript proxies where we use them to recreate Python's extended slice syntax.


JavaScript Injection with Selenium, Puppeteer, and Marionette in Chrome and Firefox
An exploration of different browser automation methods to inject JavaScript into webpages.
Comments