By Evan Sangaline | June 13, 2017
Introduction
I’ve been doing a lot of technical writing recently and, with that experience, I’ve grown to more deeply appreciate the writing of others. It’s easy to take the effort behind an article for granted when you’ve grown accustomed to there being new high-quality content posted every day on Hacker News and Twitter. The truth is that a really good article can take days or more to put together and it isn’t easy to write even one article that really takes off, let alone a steady stream of them.
Armed with my newfound admiration for people who create consistently high-quality content, I’ve been making an effort to keep track of any particularly good blogs that I come across and to read their new articles as they come out. Heck, I might even start using an RSS reader again. Is Google’s still the best one out there?
My blog collection had been growingly slowly and steadily, but, as a participation-trophy-carrying millenial, that simply wasn’t good enough for me. I wanted to find the real crème de la crème and I needed to go bigger in order to do that. So I turned to one of my favorite datasets, the Hacker News submission history, and sought out to compile a list of the best blogs out there by the most objective metrics that I could come up with. Neither my personal blog nor the Intoli blog made the cut, so there are obviously still some bugs to work out, but overall I’ve been really pleased with the results. Just kidding… mine totally made it. I’ve discovered a bunch of new (to me) writers and have had a lot of fun with the analysis behind the project.
Limiting the Data to Blogs
The raw dataset is a collection of stories submitted to Hacker News as obtained from the official Hacker News API. There were a total of 2.3 million stories linking to external URLs and, in addition to the URL, each story’s score, submission time, submitter, title, and number of comments are also known. Most of these stories, however, are not actually from blogs. In fact, only about 12.6% of them are.
To proceed with the analysis, I had to somehow make a determination of which stories were or weren’t blog submissions.
I did this by filtering on URL paths beginning with a few common prefixes: /blog/, /post/, /posts/, and /YYYY/MM/.
I also included domains that started with blog. and I added special handling of articles on Medium (medium.com/@username/) because they were so common.
This approach turned up a total 56,197 distinct blogs and 291,801 stories which were used as the basis for the analysis. I know that there are some excellent blogs out there with more exotic URL schemes that unfortunately slipped through the cracks. I apologize if your excellent blog was one of those, but manual inspection showed that this filter was enough to identify the vast majority of blog submissions.
The “Best” Blogs
So the concept of “best” is obviously a bit subjective. There are some metrics that we can gather from the Hacker News data that seem definitively good though. I would say that blogs with more total articles, larger fractions of articles making the front page, and higher mean/median/maximum scores are generally going to be better. This is of course somewhat equating success on Hacker News with quality, but- given the dataset- this is all we really have to go off of.
Even after deciding on these generally positive metrics, the question of how to combine them still remains. It turns out that there’s a fairly well-defined way to determine the “best” configurations of these distinct metrics in some sense: selecting the Pareto optimal blogs. Pareto optimality is a concept that I think is most easily demonstrated graphically. Let’s take a look at the different configurations of the number of articles a blog has produced and the fraction of them that make the front page (using scores greater than or equal to ten as an approximation for “making the front page”).
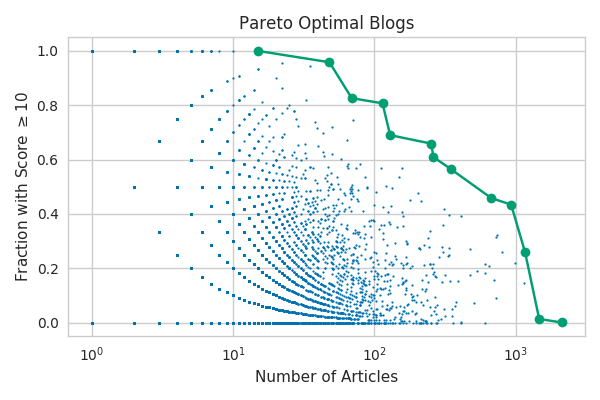
Each point on this plot represents a single blog and the larger green points are the Pareto optimal blogs which make up the Pareto frontier. The Pareto optimal blogs are the ones for which there exist no other blogs that are strictly better, where strictly better means better in at least one metric while being worse in none of them. You can see that for every non-Pareto optimal blog you can find a strictly better second blog that does better in one of the metrics and is either equivalent or better in the second metric as well. For example, a blog with 100 articles that make the front page 50% of the time would be strictly better than one that had 99 articles and made the front page 50% of the time.
We can also look at other pairs of metrics and see similar trade-offs in their relative importance along the Pareto frontier. For example, here we can see the blogs that are Pareto optimal with respect to their average and maximum scores of their submissions.
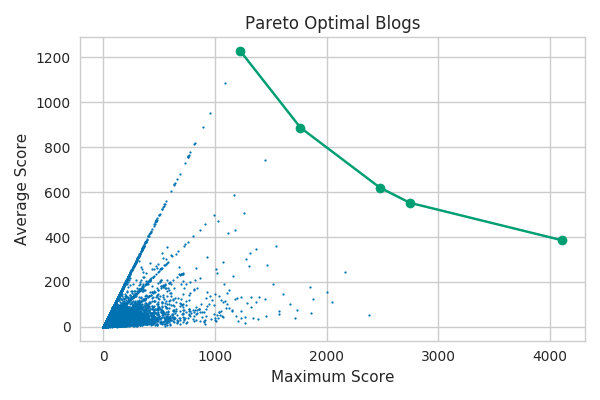
The linear patterns radiating out from the center here correspond to small integer numbers of total articles. The maximum score will exactly equal the average score for blogs with only one submission, will approximately equal twice the average score for blogs with two submissions where only one did well, etc. This particular Pareto frontier is going to be dominated by blogs with a small number of submissions, but this won’t be an issue when we find the frontier in a higher dimensional metric space including the number of articles.
The Pareto frontier will contain the best possibilities for any weighting of the relative importance of each metric. This means that it will also include some metric weightings that are probably quite far from what anybody would consider a reasonable balance. The blog with the most submissions is Pareto optimal but nearly all of the entries get no upvotes and many are flagged as spam. The poor guy had one submission get 80 votes eight years ago and he’s been chasing the dream ever since (2104 times to be precise). Similarly, the blog that has the highest scoring submission on Hacker News is certainly notable for breaking an extremely important story that garnered 4107 votes but is otherwise fairly unremarkable.
To get around this issue, I added an additional restriction that all blogs must be at least average in each metric: total number of articles, fraction with score greater than or equal to ten, average score, median score, and maximum article score. This eliminates some of the more extreme configurations while otherwise leaving the Pareto frontier unchanged. The means and standard deviations for each metric are shown in the table that follows.
| Metric | Mean | Standard Deviation |
|---|---|---|
| Total Articles | 5.19 | 22.82 |
| Front Page Fraction | 0.13 | 0.28 |
| Average Score | 10.86 | 33.86 |
| Median Score | 8.14 | 31.57 |
| Maximum Score | 29.34 | 93.22 |
After applying this minimum, the Pareto frontier consisted of 17 blogs which are shown here in order of those with the most to those with the fewest articles.
| Blog | Total Articles | Front Page Fraction | Average Score | Median Score | Maximum Score |
|---|---|---|---|---|---|
| blog.ycombinator.com | 347.00 | 0.56 | 123.17 | 22 | 1876 |
| www.gabrielweinberg.com/blog | 261.00 | 0.61 | 48.15 | 21 | 424 |
| www.catonmat.net/blog | 252.00 | 0.66 | 41.27 | 20 | 478 |
| stripe.com/blog | 156.00 | 0.57 | 103.90 | 17 | 943 |
| www.daemonology.net/blog | 129.00 | 0.69 | 83.79 | 48 | 403 |
| blog.samaltman.com | 114.00 | 0.81 | 224.58 | 169 | 1163 |
| sheddingbikes.com/posts | 69.00 | 0.83 | 84.81 | 43 | 394 |
| rethinkdb.com/blog | 64.00 | 0.58 | 103.33 | 22 | 1674 |
| blog.pinboard.in | 54.00 | 0.54 | 134.15 | 10 | 1236 |
| blog.rust-lang.org | 48.00 | 0.96 | 345.33 | 346 | 1363 |
| www.gazehawk.com/blog | 15.00 | 1.00 | 68.93 | 65 | 274 |
| josephg.com/blog | 11.00 | 0.55 | 189.91 | 15 | 1519 |
| datanitro.com/blog | 10.00 | 1.00 | 72.60 | 73 | 139 |
| www.giftrocket.com/blog | 8.00 | 1.00 | 120.75 | 129 | 207 |
| blog.jenniferdewalt.com | 8.00 | 0.62 | 360.25 | 171 | 1542 |
| varnull.adityamukerjee.net/post | 6.00 | 0.50 | 552.33 | 30 | 2744 |
| keybase.io/blog | 6.00 | 1.00 | 469.50 | 302 | 1025 |
Unsurprisingly, the official Y Combinator blog and Sam Altman’s blog both make the cut.
Then, several most of the company blogs are YC companies (e.g. Stripe, RethinkDB, GiftRocket, DataNitro, and GazeHawk).
Don’t get me wrong, these blogs all contain a lot of excellent material, but it’s interesting to note that at least 41% of the Pareto optimal blogs have some YC affiliation.
In the words of @dang, “Meta is basically crack,” and it seems likely that some of these blogs have received a little extra love due to their affiliation.
The ones that are most interesting to me are the personal blogs and, in particular, the ones that are new to me. A few standouts that I’m sure I’ll be coming back to are josephg.com/blog, www.catonmat.net/blog, and http://www.daemonology.net/blog/. Most of the others are either no longer updated or currently point to broken links.
I was honestly really hoping for some more personal blogs and ones that I hadn’t heard of. In order to eliminate some of the more well-known blogs, I decided to run the same optimization procedure on only the blogs which have been submitted by three or fewer distinct users on Hacker News. This resulted in 25 Pareto optimal blogs that do indeed seem to be tend more towards niche and personal blogs.
| Blog | Total Articles | Front Page Fraction | Average Score | Median Score | Maximum Score |
|---|---|---|---|---|---|
| blog.directededge.com | 25.00 | 0.80 | 49.40 | 39 | 167 |
| blog.jitbit.com | 24.00 | 0.54 | 60.75 | 13 | 522 |
| blog.jazzychad.net | 22.00 | 0.95 | 87.27 | 56 | 410 |
| www.gazehawk.com/blog | 15.00 | 1.00 | 68.93 | 65 | 274 |
| ryanleecarson.tumblr.com/post | 11.00 | 0.91 | 114.18 | 78 | 452 |
| blog.framebase.io | 11.00 | 0.73 | 74.82 | 16 | 486 |
| datanitro.com/blog | 10.00 | 1.00 | 72.60 | 73 | 139 |
| www.giftrocket.com/blog | 8.00 | 1.00 | 120.75 | 129 | 207 |
| sangaline.com/post | 8.00 | 0.75 | 304.38 | 86 | 1274 |
| blog.benjojo.co.uk | 8.00 | 0.75 | 193.62 | 135 | 490 |
| cam.ly/blog | 6.00 | 1.00 | 100.50 | 49 | 298 |
| varnull.adityamukerjee.net/post | 6.00 | 0.50 | 552.33 | 30 | 2744 |
| adriansampson.net/blog | 6.00 | 0.50 | 182.00 | 141 | 439 |
| blog.oldgeekjobs.com | 6.00 | 0.50 | 290.83 | 136 | 1071 |
| blog.fiplab.com | 5.00 | 0.80 | 119.00 | 153 | 166 |
| blog.ridejoy.com | 5.00 | 1.00 | 115.80 | 50 | 228 |
| goodfil.ms/blog | 5.00 | 1.00 | 156.80 | 136 | 213 |
| www.mattgreer.org/post | 4.00 | 0.75 | 198.75 | 98 | 594 |
| aaronrandall.com/blog | 4.00 | 0.75 | 143.50 | 165 | 241 |
| medium.com/@aboodman | 4.00 | 0.50 | 200.25 | 146 | 508 |
| mina.naguib.ca/blog | 3.00 | 1.00 | 203.33 | 90 | 508 |
| www.breck-mckye.com/blog | 3.00 | 1.00 | 268.33 | 66 | 675 |
| magic.io/blog | 3.00 | 1.00 | 255.67 | 296 | 456 |
| blog.vellumatlanta.com | 3.00 | 0.67 | 505.33 | 254 | 1259 |
| ml.berkeley.edu/blog | 3.00 | 1.00 | 241.67 | 337 | 378 |
I don’t know who that sangaline.com fellow is, but he sure sounds handsome. In all seriousness, I do most of my writing on the Intoli blog these days, and if you want to read more of it then feel free to come by any time. We also have an RSS feed and a monthly digest newsletter of new articles if those are more your style.
Intoli Monthly Article Newsletter
Go ahead… you know you want to.
As for the other blogs on this second list, there are a few flops and dead links in there but also some real finds. Aaron Randall’s and Ben Cox’s blogs are simply awesome. ML@B, Adrian Sampson, Matt Greer, Mina Naguib, and Jimmy Breck-McKye are also very good. Some of the smaller company blogs also seem to have a lot of great archived content: goodfil.ms/blog, cam.ly/blog/, blog.directededge.com/.
Conclusion
I’m pretty happy with the results overall. I was after a few new high quality blogs to follow and I certainly found some that I really, really like. It’s a little tricky to balance looking for blogs that you haven’t heard of with wanting to find big and popular blogs, but there were easily at least five new blogs that I’ll definitely be following now. I hope that some other people out there found one or two that are new to them as well!
Oh.. and, as always, feel free to get in touch with us if you’re looking to get some help with your own data sourcing, aggregation, or processing. We love working on unique problems and would be happy to chat about whatever it is that you’re working on!
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.

Performing Efficient Broad Crawls with the AOPIC Algorithm
Learn how to estimate page importance and allocate bandwidth during a broad crawl.

User-Agents — Generating random user agents using Google Analytics and CircleCI
A free dataset and JavaScript library for generating random user agents that are always current.
How F5Bot Slurps All of Reddit
The creator of F5Bot explains in detail how it works, and how it's able to scrape million of Reddit comments per day.
Comments