By Evan Sangaline | April 14, 2017
UPDATE: This article is updated regularly to reflect the latest information and versions. If you’re looking for instructions then skip ahead to see Setup Instructions.
NOTE: Be sure to check out Running Selenium with Headless Chrome in Ruby if you’re interested in using Selenium in Ruby instead of Python.
Background
It has long been rumored that Google uses a headless variant of Chrome for their web crawls. Over the last two years or so it had started looking more and more like this functionality would eventually make it into the public releases and, as of this week, that has finally happened. With versions 59 and onwards, it will now be possible to harness the power of V8, Blink, and the rest of Chrome in a non-graphical server environment.
This may not sound earth-shattering if you don’t deal with headless browsers very often but it’s actually a pretty big deal. To put this into context: PhantomJS, one of the current leaders in the space, has over 21k stars on GitHub and is used by companies such as Netflix and Twitter for both unit and performance testing. Vitaly Slobodin, the former maintainer of PhantomJS, had this to say after hearing the news.
I think people will switch to it, eventually. Chrome is faster and more stable than PhantomJS. And it doesn’t eat memory like crazy.
I don’t see any future in developing PhantomJS. Developing PhantomJS 2 and 2.5 as a single developer is a bloody hell. Even with recently released 2.5 Beta version with new and shiny QtWebKit, I can’t physically support all 3 platforms at once (I even bought the Mac for that!). We have no support. From now, I am stepping down as maintainer. If someone wants to continue - feel free to reach me.
From this alone, it’s pretty clear that headless Chrome is going to play an increasingly important role in the headless browser space (and headless Firefox as well, now that it’s been released). This has huge repercussions for both automated testing and web scraping.
In the web scraping world, headless browsers are particularly useful when dealing with JavaScript heavy sites. You can sometimes just fetch data from the same internal API endpoints that a JavaScript app is using but it’s becoming increasingly popular to put measures in place that prevent that. Using an actual browser lets you appear to the server in exactly the same way that a typical user would which can be highly desirable in some circumstances. Headless browsers are also a great option if you’re doing a broad crawl and want to parse DOM content without figuring out how the data is being sourced on each site.
Whether in the context of testing or web scraping, headless browsers are generally used in conjunction with software like Nightmare or Selenium to automate user interactions. Most of these are fairly comparable but Selenium is one of the most popular options and that’s what we’ll focus on in this article. Selenium uses the WebDriver API to interact with different backends (e.g. Chrome, Firefox, PhantomJS), has broad compatibility with a variety of testing frameworks, and is also widely used for web scraping.
By the end of this article, you should be able to have Selenium up and running with Chrome in its new headless mode. We’ll also take a brief look at how this setup can be used to automate interactions with Facebook. If you’re new to Selenium then this can serve as a light introduction.
Setup
The first thing we’ll need is a version of Chrome that includes the headless functionality (versions greater than or equal to 59). This was a bit tricky when only the unstable or beta channels included the functionality, but it has become relatively straightforward since version 59 hit the stable channel on June 6th, 2017. There’s a good chance that you already have a version of Google Chrome installed, and you can just use that version as long as it’s relatively up to date.
If you don’t currently have Google Chrome installed, you can simply visit the Google Chrome Download Page and install the latest version for your platform. The default Linux packages are unfortunately only available for Debian/Ubuntu and Fedora/openSUSE. If you’re using a different distribution, then you might be interested in our guide to installing Google Chrome on CentOS, RHEL, and Amazon Linux or the Arch Linux AUR package for Google Chrome.
After installing the stable version of Google Chrome, we’ll need to set up a virtualenv and install our main dependencies.
# make the project directory
mkdir -p ~/scrapers/facebook
cd ~/scrapers/facebook
# create and activate a virtualenv
virtualenv env
. env/bin/activate
# install selenium locally
pip install selenium
# provides a nice repl, not needed for selenium
pip install ipython
We’ll also need to install a compatible version of ChromeDriver in order to connect Selenium to a headless Chrome instance. Any version since 2.29 should work fine with headless mode, but obviously newer versions will include more recent bug fixes and feature additions. On macOS you can install ChromeDriver using Homebrew
brew install chromedriver
while on Arch Linux it can be installed from the ChromeDriver AUR package.
Another alternative is to just grab the latest binaries for your platform directly from Google.
This is actually my preferred method because they tend to be more up to date than system packages and the same installation procedure can be used accross multiple platforms.
The chromedriver binary simply needs to be somewhere in your executable path in order to work with Selenium, so one trick is to just install the latest binary locally in your virtualenv’s binary path.
This code will automatically find the latest release and install the binary locally in env/bin/.
# platform options: linux32, linux64, mac64, win32
PLATFORM=linux64
VERSION=$(curl http://chromedriver.storage.googleapis.com/LATEST_RELEASE)
curl http://chromedriver.storage.googleapis.com/$VERSION/chromedriver_$PLATFORM.zip \
| bsdtar -xvf - -C env/bin/
If you’re on macOS then you’ll want to replace linux64 with mac64 or if you’re on Windows… well, if you’re on Windows then I hear that Windows Subsystem for Linux isn’t actually all that bad.
Once those commands complete, you can check that you selected the correct platform and that it downloaded OK by running the chromedriver command and verifying that it produces an output something like this.
(env) [sangaline@freon facebook]$ chromedriver
Starting ChromeDriver 2.33.506092 (733a02544d189eeb751fe0d7ddca79a0ee28cce4) on port 9515
Only local connections are allowed.
If you get an error instead then you should double check that you chose the correct platform (perhaps try linux32 instead of linux64).
Once you can run chromedriver successfully, the basic setup process is complete!
Interested in Headless Web Scraping?
Our web scraping experts would love to help you source data from sites which are JavaScript heavy or have anti-scraping mechanisms like captchas and ip bans in place. We provide customized API feeds and data processing that are designed to meet your specific needs no matter how unique they might be.
Get started nowConfiguring Selenium
We’ll work within an interactive IPython shell here so that we can enter a few commands at a time.
We already installed this in the virtualenv earlier so we simply have to run ipython to drop into a REPL.
Now let’s begin configuring Selenium to work with headless Chrome.
We’ll do this by first creating a ChromeOptions object that we can use to configure the options that will be passed to the WebDriver initializer.
from selenium import webdriver
options = webdriver.ChromeOptions()
If you’re using the stable channel, then ChromeDriver should be able to find the Chrome executable automatically.
You might, however, prefer to use the development or beta channel versions instead.
In that case, you’ll need to specify the alternative location for the Google Chrome executable.
You can skip this step if you don’t have a good reason to use a version other than stable (e.g. you want to use some new experimental features).
The unstable executable is most likely located at /usr/bin/google-chrome-unstable on Linux and /Applications/Google Chrome 2.app/Contents/MacOS/Google Chrome on the operating system formerly known as OS X (note that it needs to be the full path to the binary and not just the application directory).
Once you figure out the binary location and verify that you can launch the unstable executable from the command line, then specify the binary_location on our ChromeOptions object.
# tell selenium to use the dev channel version of chrome
# NOTE: only do this if you have a good reason to
options.binary_location = '/usr/bin/google-chrome-unstable'
We will also need to specify that Chrome should be started in headless mode.
This can be done with the add_argument method
options.add_argument('headless')
which is equivalent to adding --headless as a command-line argument.
You can now specify any additional options and then finally initialize the driver.
# set the window size
options.add_argument('window-size=1200x600')
# initialize the driver
driver = webdriver.Chrome(chrome_options=options)
If nothing happens then everything worked! Normally, a new browser window would pop open at this point with a warning about being controlled by automated test software. It not appearing is exactly what we want to happen in headless mode and it means that we could be running our code on a server that doesn’t even have a graphical environment. Everything from here on out is just standard Selenium so if you were only trying to figure out how to get it working with Chrome in headless mode then that’s it!
Interacting With Facebook
Now that we have a WebDriver hooked up to a headless Chrome instance, we can use the standard Selenium API to run tests, scrape websites, or do whatever else we might be interested in. Let’s poke around on Facebook to see a little bit of what we can do. To call Facebook a “JavaScript heavy” site is a bit of an understatement so it serves as a good example of where headless browsers can be really useful.
We’ll start by navigating to the Facebook main page and grabbing the login form elements.
driver.get('https://facebook.com')
# wait up to 10 seconds for the elements to become available
driver.implicitly_wait(10)
# use css selectors to grab the login inputs
email = driver.find_element_by_css_selector('input[type=email]')
password = driver.find_element_by_css_selector('input[type=password]')
login = driver.find_element_by_css_selector('input[value="Log In"]')
The find_element_by_css_selector calls here will block until the elements are ready (thanks to implicitly_wait), so we’re immediately ready to enter our login credentials.
email.send_keys('evan@intoli.com')
password.send_keys('hunter2')
Let’s take a quick screenshot to make sure that everything looks good so far before we actually submit the login form.
driver.get_screenshot_as_file('main-page.png')
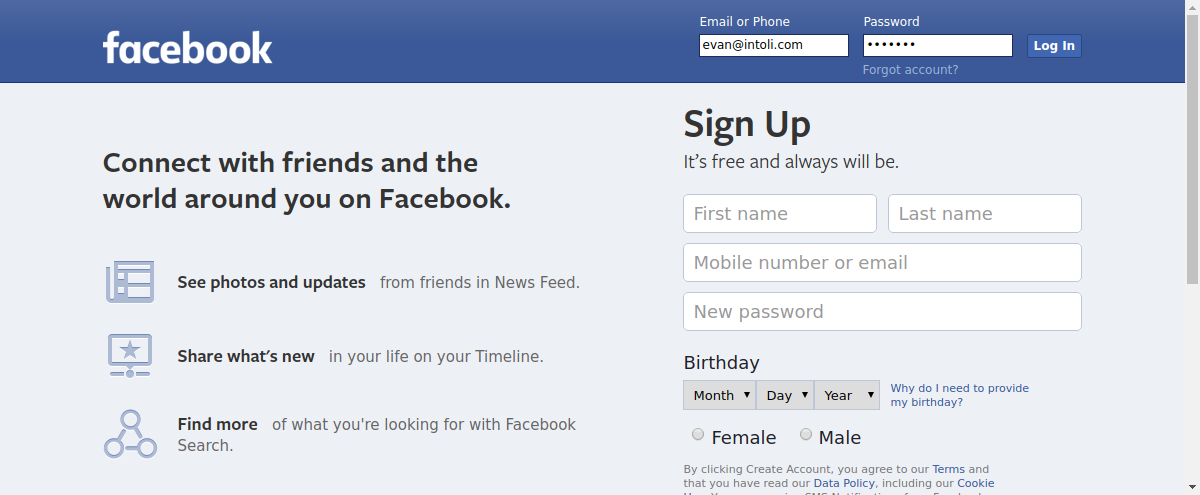
That seems about right, so now let’s proceed with actually submitting the form.
# login
login.click()
# navigate to my profile
driver.get('https://www.facebook.com/profile.php?id=100009447446864')
# take another screenshot
driver.get_screenshot_as_file('evan-profile.png')
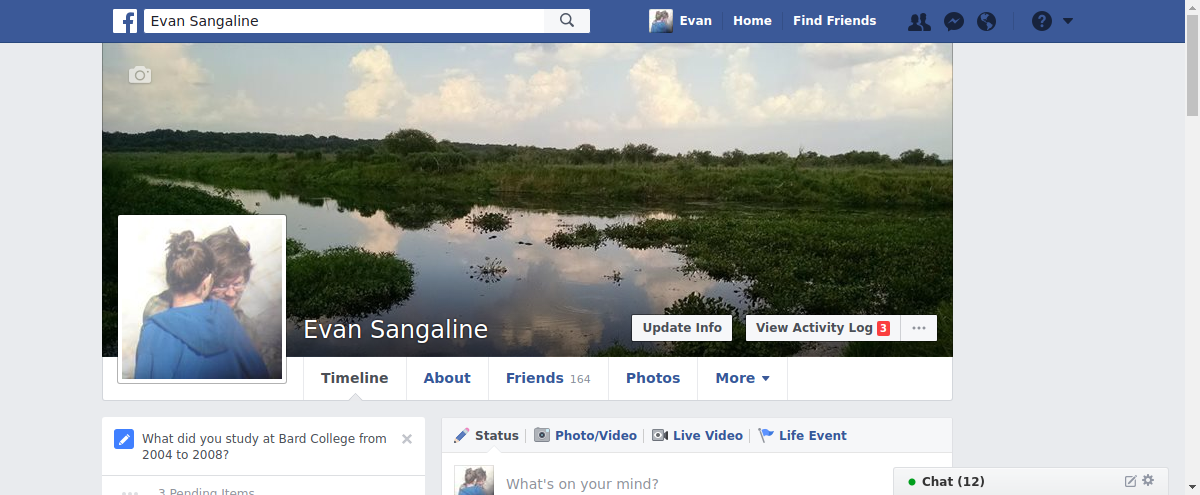
You can see that we’ve logged in successfully and can browse around as we please. At this point, we could easily write code to automate adding new posts, scraping content, or basically anything else that we could do by hand. Let’s do one last scraping related activity before we wrap it up.
posts = driver.find_elements_by_css_selector('#stream_pagelet .fbUserContent')
for post in posts:
try:
author = post.find_elements_by_css_selector('a[data-hovercard*=user]')[-1].get_attribute('innerHTML')
content = post.find_elements_by_css_selector('div.userContent')[-1].get_attribute('innerHTML')
except IndexError:
# it's an advertisement
pass
print(f'{author}: "{content}"')
This will print out the name and text content of each post on your Facebook feed. It’s a very simplified example but it’s easy to imagine how you could build a much more powerful scraper in a similar way.
Wrap Up
We’ve covered the process of running Selenium with the new headless functionality of Google Chrome. Some components of headless mode were a little bit buggy when this article was first written, but we’ve been using it in production since it hit the stable channel and we think that it’s ready for prime time now. We suspect that a lot of exciting new projects are going to spring up around headless Chrome and we’re really looking forward to seeing what the future holds.
If you have any feedback or are looking for help putting together your own data solutions then please don’t hesitate to get in touch!
Suggested Articles
If you enjoyed this article, then you might also enjoy these related ones.
Breaking Out of the Chrome/WebExtension Sandbox
A short guide to breaking out of the WebExtension content script sandbox.

Recreating Python's Slice Syntax in JavaScript Using ES6 Proxies
A gentle introduction to JavaScript proxies where we use them to recreate Python's extended slice syntax.
Building a YouTube MP3 Downloader with Exodus, FFmpeg, and AWS Lambda
A short guide to building a practical YouTube MP3 downloader bookmarklet using Amazon Lambda.
Comments